决策树
决策树是一个非参数的监督式学习方法,主要用于分类和回归,算法的目标是通过推断数据特征,学习决策规则从而创建一个预测目标变量的模型。决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:
- 决策树模型可以读性好,具有描述性,有助于人工分析;
- 效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
决策树既可以做分类,也可以做回归。
- 分类树的输出是样本的类标。
- 回归树的输出是一个实数 (例如房子的价格,病人呆在医院的时间等)。
分类
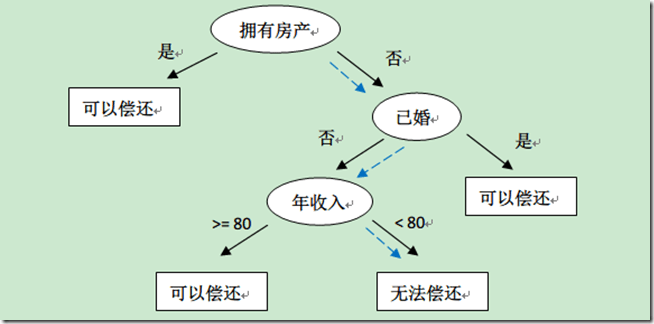
以文章开始的图片为例子,假设银行贷款前需要审查用户信息,来确定是否批准贷款,构造数据 data.scv 如下:
house, married, income, give_loan
1, 1, 80, 1
1, 0, 30, 1
1, 1, 30, 1
0, 1, 30, 1
0, 1, 40, 1
0, 0, 80, 1
0, 0, 78, 0
0, 0, 70, 1
0, 0, 88, 1
0, 0, 45, 0
0, 1, 87, 1
0, 0, 89, 1
0, 0, 100, 1
1 | from numpy import genfromtxt |
回归
回归和分类不同的是向量 y 可以是浮点数。
1 | from sklearn import tree |
scikit-learn 官网给出的例子是:
1 | import numpy as np |
决策树的使用
- 如果数据量大,决策树容易过拟合。样本和特征的比例非常重要。如果决策树样本少,特征多,非常可能过拟合。
- 可以考虑事先做维度约减(PCA,ICA),以产生一个特征之间区别性大的决策树
- 通过 export 将你的训练的决策树可视化,使用 max_depth =3 作为一个初始的树的深度,有一个数据拟合决策树模型的大概感觉,然后逐渐增加深度
数据的样本量的增加将加深决策树的深度,使用 max_depth 控制决策树的尺寸以防止过拟合 - 使用 min_samples_split 或者 min_samples_leaf 来控制叶节点的样本数量。一个非常小的数量往往意味着过拟合,而一个较大的数可以防止过拟合。可以将 min_samples_leaf=5 作为一个初始值。如果样本数据变化巨大,可以采用一个浮点数。两者的区别在于 min_samples_leaf 保证了叶节点最小的数量,min_samples_split 能够建立任意数量的叶子节点,在文学上用到也更多
- 如果样本是有权重的,可以使用 min_weight_fraction_leaf 来实现基于权重的预修剪规则来优化决策树结构
- 决策树内部使用 np.float32 向量,如果样本不是这个形式的,将产生一个数据集的样本
- 如果数据矩阵 X 是非常稀疏的,建议在拟合和预测之前转换为稀疏矩阵 csc_matrix。稀疏矩阵将比稠密矩阵快数量级的速度