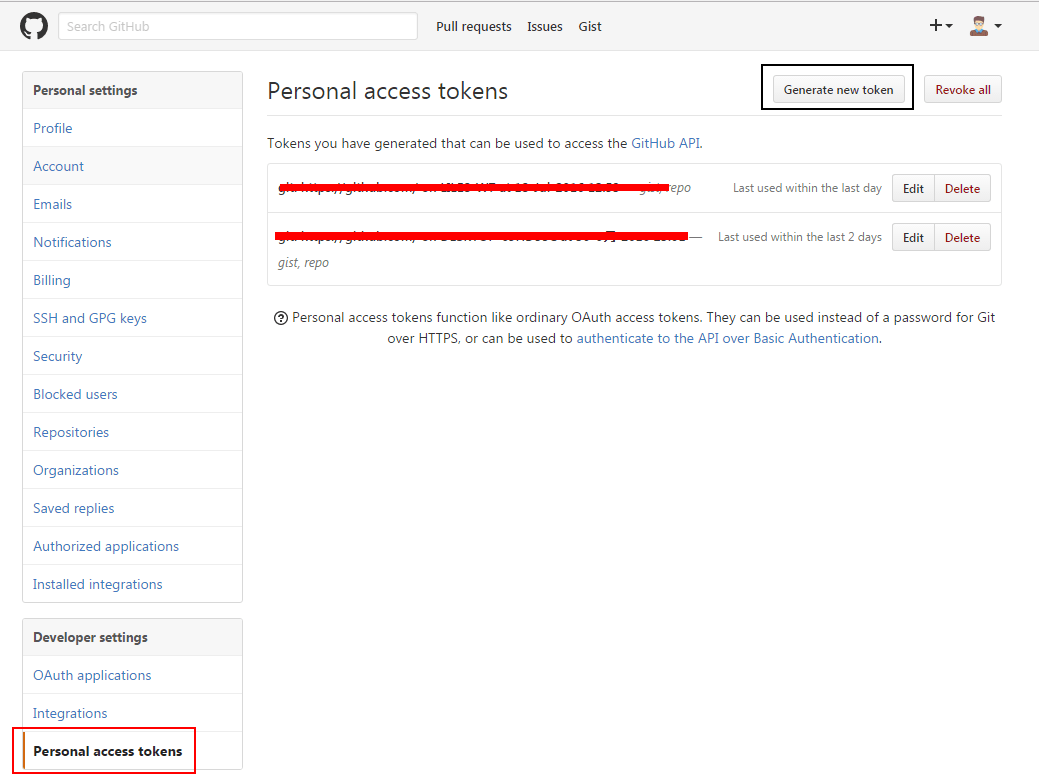
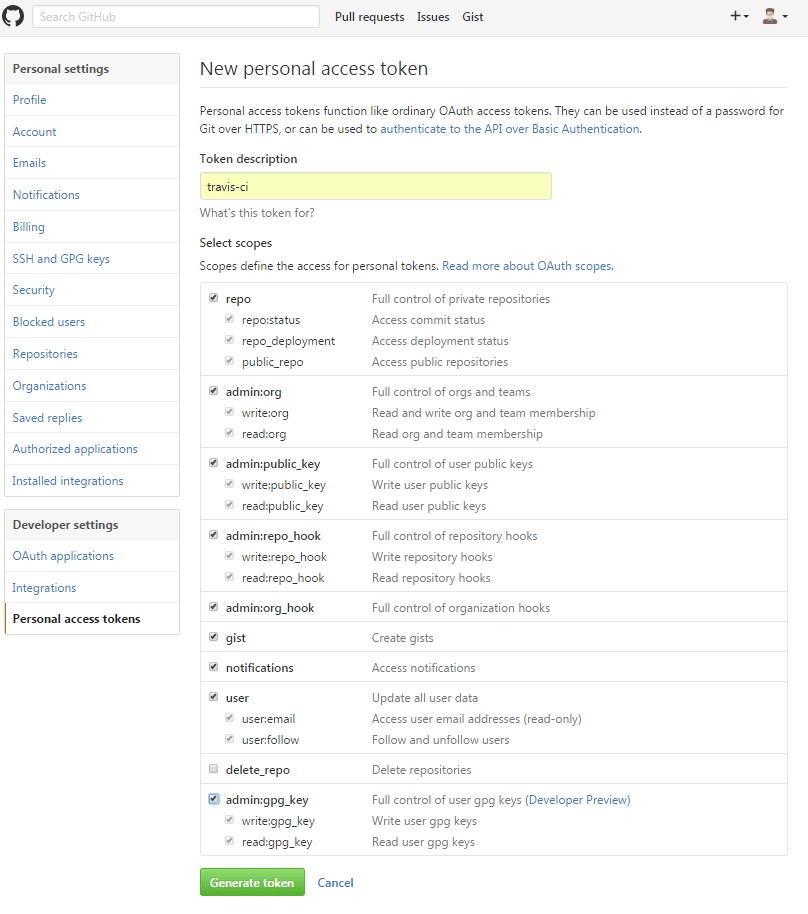
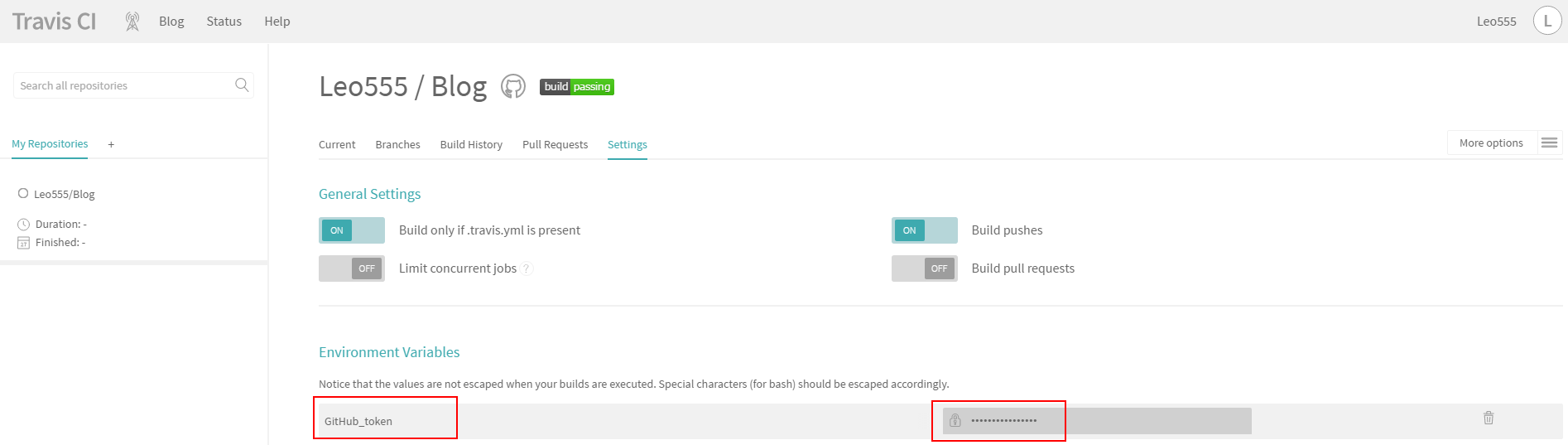
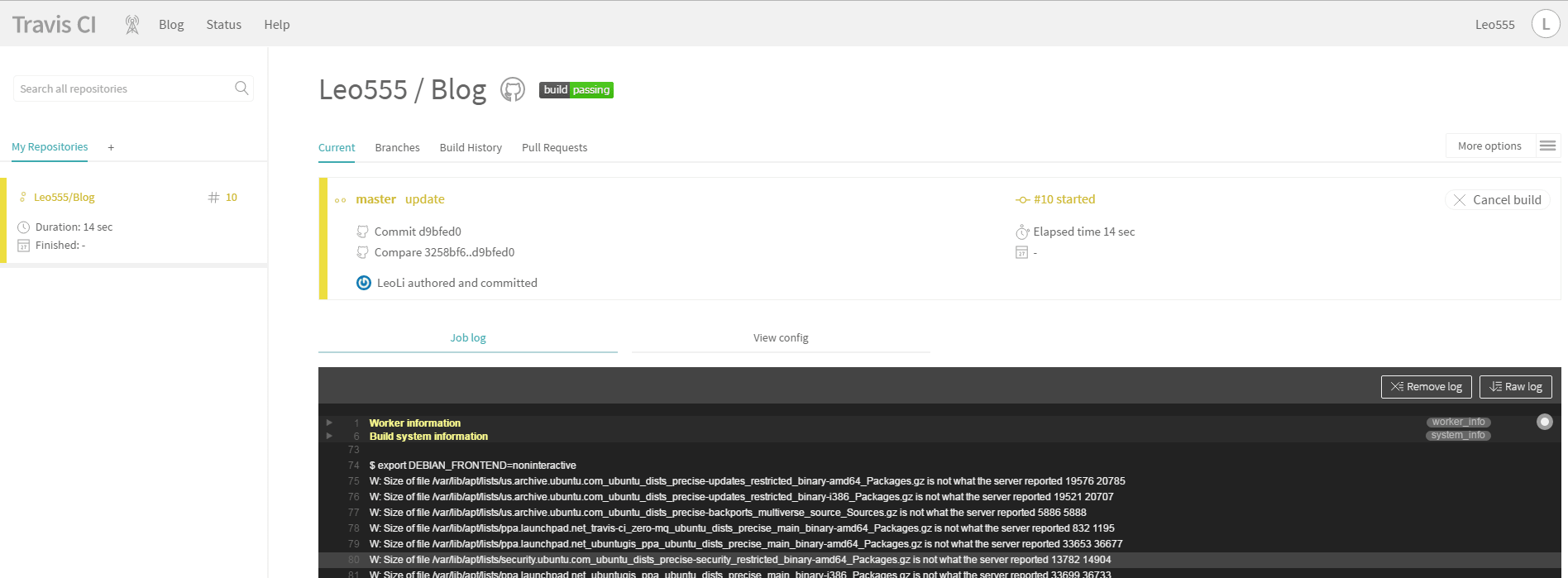
You can use the built-in Node Worker Pool by developing a C++ addon. On older versions of Node, build your C++ addon using NAN, and on newer versions use N-API. node-webworker-threads offers a JavaScript-only way to access Node’s Worker Pool.
React Hooks 是对 React function 组件的一种扩展,通过一些特殊的函数,让无状态组件拥有状态组件才拥有的能力。
Hooks 是 React 函数组件中的一类特殊函数,通常以 use 开头,比如 useRef,useState,useReducer 等。通常在我们写 React 组件的时候,如果这个组件比较复杂,拥有自己的生命周期或者 state,就将其写成 class 组件;如果这个组件仅仅用来展示,就将其写成 function 组件。
React Hooks 使用 function 组件的写法,通过 useState 这样的 API 解决了 function 组件没有 state 的问题,通过 useEffect 来解决生命周期的问题,通过自定义 hooks 来复用业务逻辑。
Hooks 解决哪些问题
复用与状态有关的逻辑,之前引申出来 HOC 的概念,但是 HOC 会导致组件树的臃肿。
解决组件随着业务扩展变得难以维护的问题。
使用更容易理解并且对初学者更友好的 function 组件。
用法
Hooks 主要分三种:
State hooks: 允许开发者在 function 组件中使用 state。
Effect hooks: 允许开发者在 function 组件中使用生命周期和 side effect。
Custom hooks: 自定义 hooks,可以在里面使用 State Hooks 和 Effect Hooks,达到组件之间逻辑复用。
// Similar to componentDidMount and componentDidUpdate: useEffect(() => { // Update the document title using the browser API document.title = `You clicked ${count} times`; });
在 Web 开发中,使用 CDN 资源可以有效减少网络请求时间,但是使用 CDN 资源也存在一个问题,CDN 资源存在于第三方服务器,在安全性上并不完全可控。
CDN 劫持是一种非常难以定位的问题,首先劫持者会利用某种算法或者随机的方式进行劫持(狡猾大大滴),所以非常难以复现,很多用户出现后刷新页面就不再出现了。之前公司有同事做游戏的下载器就遇到这个问题,用户下载游戏后解压不能玩,后面通过文件逐一对比找到原因,原来是 CDN 劫持导致的。怎么解决的呢?听说是找 xx 交了保护费,后面也是利用文件 hash 的方式,想必原理上也是跟 SRI 相同的。
$ kong check /etc/kong/kong.conf # 检验 kong 配置文件是否正确 $ kong migrations up [-c /etc/kong/kong.conf] # 通过配置文件准备数据存储 $ kong start [-c /etc/kong/kong.conf] # 启动 kong $ kong stop $ kong reload
腾讯的面试很细节,个人感觉是需要提前查漏补缺的,从 api 到设计到原理还有算法都有涉猎。面 alloyteam 的时候,面试官的问题种种都是 “你觉得 a 比 b 相比怎么样”,“使用 a 技术开发某某可能会遇到什么问题”,“某某某为什么选择这样的设计” 这样很开放性的问题,感觉自己回答的都不是很好。后面通过同事咨询面试官,得到的答复是他还在考虑,然后就没有然后了。毕竟是腾讯的明星组,想进入还是有难度的。
Symbol() 函数返回 symbol 类型的值,该类型具有静态属性和静态方法,并且不支持 new Symbol() 语法。每个从 Symbol() 函数中返回的 symbol 值都是唯一的。一个 symbol 值能作为对象属性的标识符,这是该数据类型最大的目的。
Symbol vs symbol
Symbol 是一个不支持 new 操作符的函数,用于创建 symbol 类型的值。
symbol 是一种基本数据类型。目前 JavaScript 支持的 7 种数据类型是:undefined、null、Boolean、String、Number、Object、symbol。
Symbol 使用
我们可以直接使用 Symbol() 函数创建 symbol 类型,并且用一个字符串作为其描述,每次都会创建一个新的 symbol 类型。
1 2 3 4 5 6 7 8
let a = Symbol() typeof a // 'symbol' Object.prototype.toString.call(a) // '[object Symbol]' let a1 = Symbol('a') let a2 = Symbol('a') a1 == a2 // false a1 === a2 // false Symbol('foo') === Symbol('foo') // false
Symbol() 函数不能使用 new 操作符。因为 JavaScript 中 new 操作符用来创建对象,Symbol 生成的是一个原始类型的值,并不是对象。通过原始数据类型创建一个显式包装器对象的方式从 ECMAScript 6 开始不再被支持。 然而现有的原始包装器对象,如 new Boolean()、new String() 以及 new Number() 因为遗留原因仍可被创建。
1
newSymbol() // TypeError: Symbol is not a constructor at new Symbol
Symbol 可以接收字符串或者对象作为参数,如果参数是对象的话,Symbol 会调用该对象的 toString() 方法,将其转换为字符串,再生成 symbol 值。
1 2 3 4 5 6 7
let a = { toString () { return'abc' } } let sa = Symbol(a) sa // Symbol(abc)
Symbol 值不能与其它数据类型的值进行运算,但是 Symbol 值可以显式转换为字符串或者 Boolean,其它类型的转换都会报 TypeError 错误。
1 2 3 4 5 6 7
let a = Symbol('World') 'Hello ' + a // TypeError: Cannot convert a Symbol value to a string `Hello ${a}`// TypeError: Cannot convert a Symbol value to a string a.toString() // 'Symbol(World)' String(a) // 'Symbol(World)' Boolean(a) // true !a // false
每一个 Symbol 函数生成的值都不相等,因此 Symbol 可以作为标识符,当做对象属性名,这样就可以保证不会出现相同的属性名。这可以有效避免属性被覆盖。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
let a = Symbol() // 第一种写法 let obj = {} obj[a] = 'Hello' // 第二种写法 let obj = { [a]: 'Hello' } // 第三种写法 let a = {} Object.defineProperty(a, mySymbol, {value: 'Hello'})
// 以上写法都得到同样结果 a[mySymbol] // 'Hello'
注意,Symbol 值作为对象属性名时,不能用点运算符,因为点运算符后面是字符串,而 symbol 值并不是字符串。
1 2 3 4 5 6
let a = Symbol() let obj = {}
obj.a = 'Hello!'// 此时 a 相当于一个字符串,并不是 a 值 obj[a] // undefined obj['a'] // 'Hello!'
在对象内部使用 Symbol 的时候,必须放在方括号中。
1 2 3 4 5
let a = Symbol() let obj = { [a]: function(arg){...} } obj[a](123)
const regenerate = require('regenerate') const codePoints = require('unicode-9.0.0/Script/Greek/code-points.js') constset = regenerate(codePoints) set.toString() // → '[\u0370-\u0373\u0375-\u0377\u037A-\u037D\u037F\u0384\u0386\u0388-\u038A\u038C\u038E-\u03A1\u03A3-\u03E1\u03F0-\u03FF\u1D26-\u1D2A\u1D5D-\u1D61\u1D66-\u1D6A\u1DBF\u1F00-\u1F15\u1F18-\u1F1D\u1F20-\u1F45\u1F48-\u1F4D\u1F50-\u1F57\u1F59\u1F5B\u1F5D\u1F5F-\u1F7D\u1F80-\u1FB4\u1FB6-\u1FC4\u1FC6-\u1FD3\u1FD6-\u1FDB\u1FDD-\u1FEF\u1FF2-\u1FF4\u1FF6-\u1FFE\u2126\uAB65]|\uD800[\uDD40-\uDD8E\uDDA0]|\uD834[\uDE00-\uDE45]' // Imagine there’s more code here to save this pattern to a file.
var cp = require('child_process') cp.spawn('node', ['worker.js']) cp.exec('node worker.js', function (err, stdout, stderr) { // some code }) cp.execFile('worker.js', function (err, stdout, stderr) { // some code }) cp.fork('./worker.js')
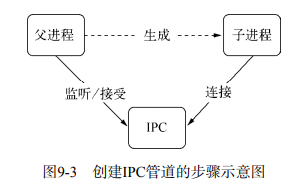
进程之间的通信
首先来看一个示例:
parent.js
1 2 3 4 5 6
var cp = require('child_process') var n = cp.fork(__dirname + '/sub.js') n.on('message', function (m) { console.log('PARENT got message:', m) }) n.send({hello: 'world'})
sub.js
1 2 3 4
process.on('message', function (m) { console.log('CHILD got message:', m) }) process.send({foo: 'bar'})
var child = require('child_process').fork('child.js') // Open up the server object and send the handle var server = require('net').createServer() server.on('connection', function(socket) { socket.end('handled by parent\n') }) server.listen(1337, function() { child.send('server', server) })
子进程 child.js:
1 2 3 4 5 6 7
process.on('message', function(m, server) { if (m === 'server') { server.on('connection', function(socket) { socket.end('handled by child\n') }) } })
通过 node 启动查看效果:
1 2 3 4 5 6 7 8 9 10 11
// 先启动服务器 $ node parent.js // 使用 curl 工具 $ curl "http://127.0.0.1:1337" handled by parent $ curl "http://127.0.0.1:1337" handled by child $ curl "http://127.0.0.1:1337" handled by child $ curl "http://127.0.0.1:1337" handled by parent
可以看出父子进程都有可能处理客户端请求。
尝试将服务发送给多个子进程。
1 2 3 4 5 6 7 8 9 10 11 12 13
// parent.js var cp = require('child_process') var child1 = cp.fork('child.js') var child2 = cp.fork('child.js') // Open up the server object and send the handle var server = require('net').createServer() server.on('connection', function(socket) { socket.end('handled by parent\n') }) server.listen(1337, function() { child1.send('server', server) child2.send('server', server) })
子进程将进程 ID 打印出来。
1 2 3 4 5 6 7 8
// child.js process.on('message', function(m, server) { if (m === 'server') { server.on('connection', function(socket) { socket.end('handled by child, pid is ' + process.pid + '\n') }) } })
// parent.js var cp = require('child_process') var child1 = cp.fork('child.js') var child2 = cp.fork('child.js') // Open up the server object and send the handle var server = require('net').createServer() server.listen(1337, function() { child1.send('server', server) child2.send('server', server) // 关闭 server.close() })
对子进程进行改动
1 2 3 4 5 6 7 8 9 10 11 12 13
// child.js var http = require('http') var server = http.createServer(function(req, res) { res.writeHead(200, { 'Content-Type': 'text/plain' }) res.end('handled by child, pid is ' + process.pid + '\n') }) process.on('message', function(m, tcp) { if (m === 'server') { tcp.on('connection', function(socket) { server.emit('connection', socket) }) } })
var crypto = require('crypto') var magic = '258EAFA5-E914-47DA-95CA-C5AB0DC85B11' var val = crypto.createHash('sha1') .update(secWebSocketKey + magic) .digest('bash64')
var net = require('net') var server = net.createServer(function(socket) { socket.write('Echo server\r\n') socket.pipe(socket) }) server.listen(1337, '127.0.0.1')
function (req, res) { var buffers = [] req.on('data', function (trunk) { buffers.push(trunk) }).on('end', function () { var buffer = Buffer.concat(buffers) res.end('') }) }
iconv-lite 由纯 JavaScript 实现,iconv 则是通过 C++ 调用 libiconv 库实现,前者比后者更轻量,无需编译和处理环境依赖。
1 2 3 4 5
var iconv = require('iconv-lite') // Buffer 转字符串 var str = icon.decode(buf, 'win1251') // 字符串转 Buffer var buf = iconv.encode('Sample input string', 'win1251')
Buffer 拼接
Buffer 常用于从输入流中读取内容
1 2 3 4 5 6 7 8 9
var fs = require('fs') var rs = fs.createReadStream('./test.md') var data = '' rs.on('data', function (chunk) { data += chunk }) rs.on('end', function (chunk) { console.log(data) })
Server Software: Server Hostname: 127.0.0.1 Server Port: 8001
Document Path: / Document Length: 10240 bytes
Concurrency Level: 200 Time taken for tests: 13.104 seconds Complete requests: 50000 Failed requests: 0 Write errors: 0 Total transferred: 515750000 bytes HTML transferred: 512000000 bytes Requests per second: 3815.61 [#/sec] (mean) Time per request: 52.416 [ms] (mean) Time per request: 0.262 [ms] (mean, across all concurrent requests) Transfer rate: 38435.54 [Kbytes/sec] received
Connection Times (ms) min mean[+/-sd] median max Connect: 0 16 129.3 1 3014 Processing: 7 35 10.2 38 255 Waiting: 1 34 10.4 37 254 Total: 7 51 130.0 39 3047
Percentage of the requests served within a certain time (ms) 50% 39 66% 40 75% 40 80% 40 90% 43 95% 52 98% 56 99% 1040 100% 3047 (longest request)
测试的 QPS(每秒查询次数)为 3815.61,传输率为 38435.54。 去掉 helloworld = new Buffer(helloworld) 前面的注释,再次测试:
Server Software: Server Hostname: 127.0.0.1 Server Port: 8001
Document Path: / Document Length: 10240 bytes Concurrency Level: 200 Time taken for tests: 7.260 seconds Complete requests: 50000 Failed requests: 0 Write errors: 0 Total transferred: 515750000 bytes HTML transferred: 512000000 bytes Requests per second: 6886.98 [#/sec] (mean) Time per request: 29.040 [ms] (mean) Time per request: 0.145 [ms] (mean, across all concurrent requests) Transfer rate: 69374.22 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 7 71.0 2 1012 Processing: 7 17 10.1 14 417 Waiting: 7 15 10.3 12 401 Total: 10 24 72.7 16 1234 Percentage of the requests served within a certain time (ms) 50% 16 66% 17 75% 18 80% 18 90% 30 95% 32 98% 41 99% 48 100% 1234 (longest request)
测试的 QPS(每秒查询次数)为 6886.98,传输率为 69374.22。性能提升了近一倍。
通过预先转换静态内容为 Buffer 对象,可以有效减少 CPU 重复使用,节省服务器资源。在 Node 构建的 Web 应用中,可以选择将页面中的动态内容和静态内容分类,静态内容预先转换为 Buffer 对象,使性能得到提升。由于文件本身是二进制数据,所以在不需要改变内容的场景中,设置 Buffer 为只读,不做额外的转换能达到更好的效果。
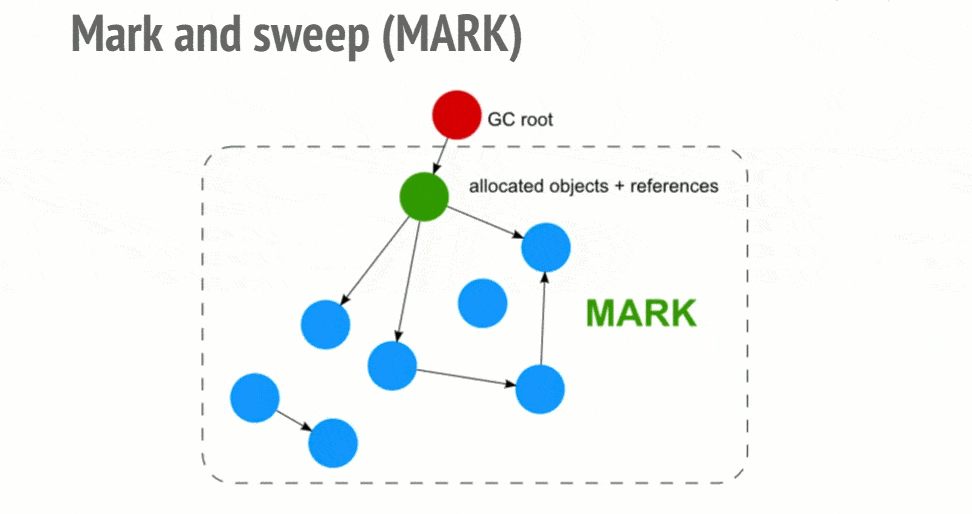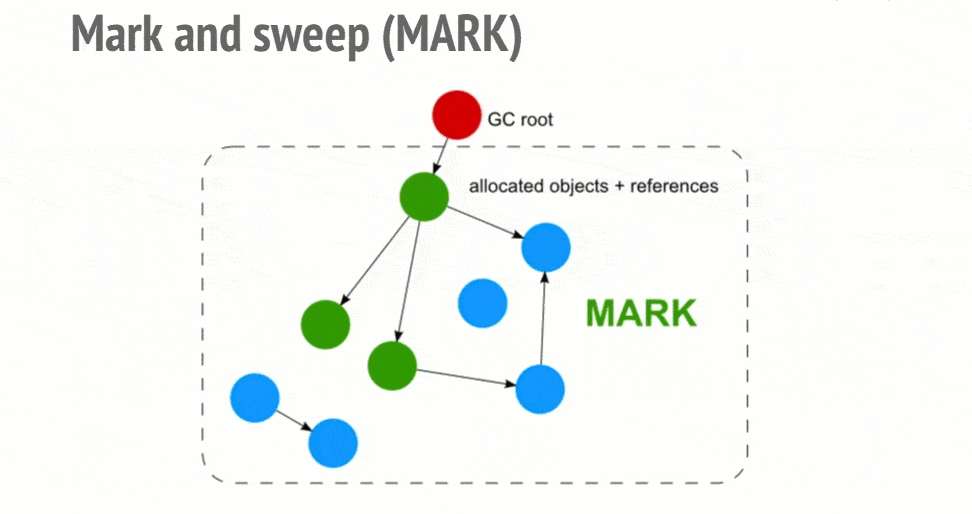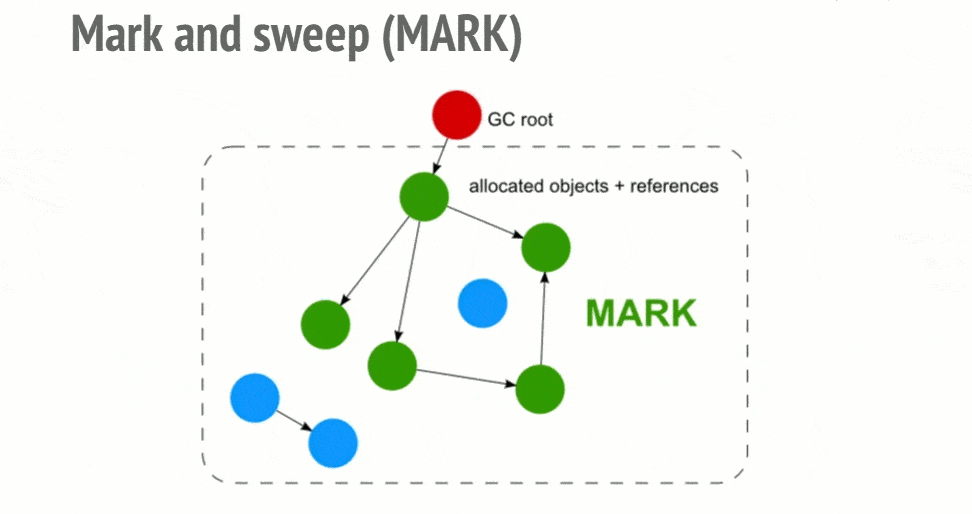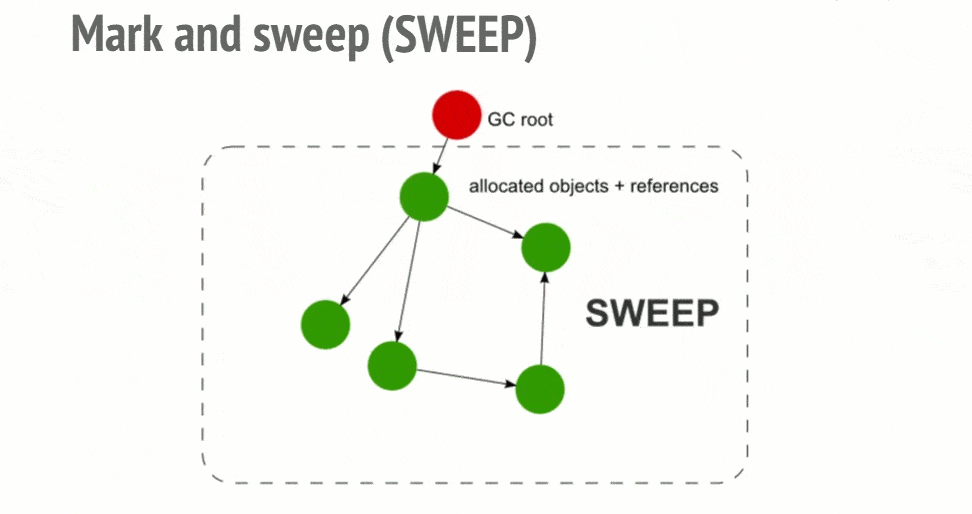
Cheney 算法是一种采用复制的方式实现的垃圾回收算法,它将堆内存一分为二,每份空间称为 semispace,两份堆内存一个处于使用中,一个处于闲置状态。处于使用状态的的空间称为 From 空间,处于闲置状态的空间称为 To 空间。当我们分配对象时,首先在 From 空间分配,当开始进行垃圾回收时,会检查 From 中存活的对象,将其复制到 To 空间中,非存活对象占用的空间将被释放。
var reader = fs.createReadStream('in.txt') var writer = fs.createWriteStream('out.txt') reader.on('data', function (chunk) { writer.write(chunk) }) reader.on('end', function () { writer.end() })
或者使用管道方法
1 2 3
var reader = fs.createReadStream('in.txt') var writer = fs.createWriteStream('out.txt') reader.pipe(writer)
缓存技术几乎存在于网络技术发展的各个角落,从数据库到服务器,从服务器到网络,再从网络到客户端,缓存随处可见。跟前端有关的缓存技术主要有:DNS 缓存,HTTP 缓存,浏览器缓存,HTML5 缓存(localhost/manifest)和 service worker 中的 cache api。
DNS 缓存
当用户在浏览器中输入网址的地址后,浏览器要做的第一件事就是解析 DNS:
(1) 浏览器检查缓存中是否有域名对应的 IP,如果有就结束 DNS 解析过程。浏览器中的 DNS 缓存有时间和大小双重限制,时间一般为几分钟到几个小时不等。DNS 缓存时间过长会导致如果 IP 地址发生变化,无法解析到正确的 IP 地址;时间过短会导致浏览器重复解析域名。
(2) 如果浏览器缓存中没有对应的 IP 地址,浏览器会继续查找操作系统缓存中是否有域名对应的 DNS 解析结果。我们可以通过在操作系统中设置 hosts 文件来设置 IP 与域名的关系。
(3) 如果还没有拿到解析结果,操作系统就会把域名发送给本地区的域名服务器(LDNS),LDNS 通常由互联网服务提供商(ISP)提供,比如电信或者联通。这个域名服务器一般在城市某个角落,并且性能较好,当拿到域名后,首先也是从缓存中查找,看是否有匹配的结果。一般来说,大多数的 DNS 解析到这里就结束了,所以 LDNS/ISP DNS 承担了大部分的域名解析工作。如果缓存中有 IP 地址,就直接返回,并且会被标记为非权威服务器应答。
第三步有一点需要注意的是,如果用户在自己电脑里设置了 DNS,比如 Google 的 8.8.8.8 或者 CloudFlare 新出的 1.1.1.1,将不会通过 ISP DNS 服务器解析。
(4) 如果前面三步还没有命中 DNS 缓存,那只能到 Root Server 域名服务器中请求解析了。根域名服务器拿到请求后,首先判断域名是哪个顶级域名下的,比如 .com, .cn, .org 等,全球一共 13 台顶级域名服务器。根域名服务器返回对应的顶级域名服务器(gTLD Server)地址。
(5) 本地域名服务器(LDNS)拿到地址后,向 gTLD Server 发送请求,gTLD 服务器查找并且返回此域名对应的 Name Server 域名服务器地址。这个 Name Server 通常就是用户注册的域名服务器,例如用户在某个域名服务提供商申请的域名,那么这个域名解析任务就由这个域名提供商的服务器来完成。
PC 端因为浏览器有域名并发请求限制(chrome 为 6 个),也就是同一时间,浏览器最多向同一个域名发送 6 个请求,因此 PC 端使用域名发散策略,将 http 静态资源放入多个域名/子域名中,以保证资源更快加载。常见的办法为使用 cdn。
域名收敛
将静态资源放在同一个域名下,减少 DNS 解析的开销。域名收敛是移动互联网时代的产物,在 LDNS 没有缓存的情况下,DNS 解析占据一个请求的大多数时间,因此,采用尽可能少的域名对整个页面加载速度有显著的提高。
(4) HttpDNS
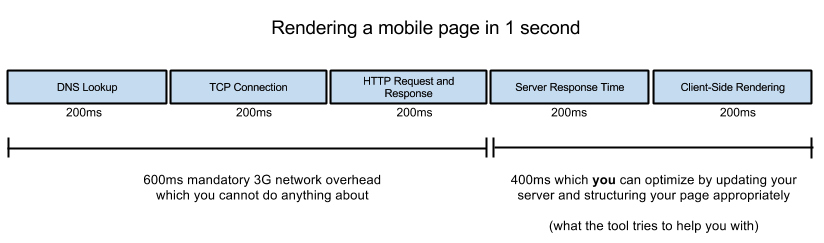
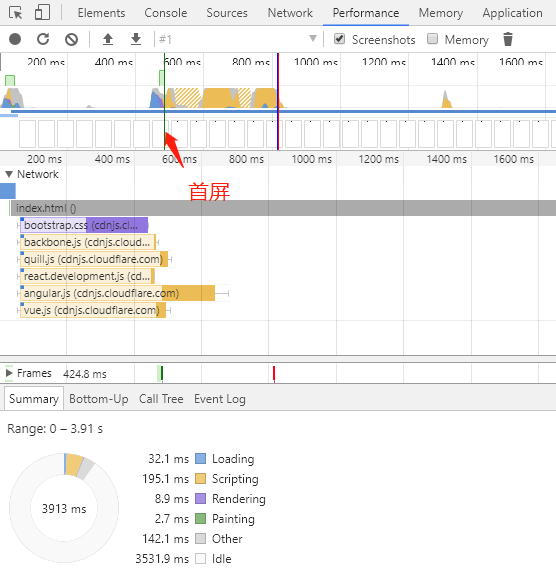
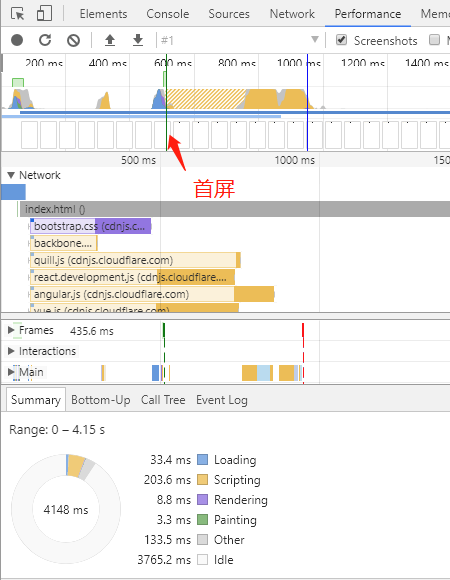
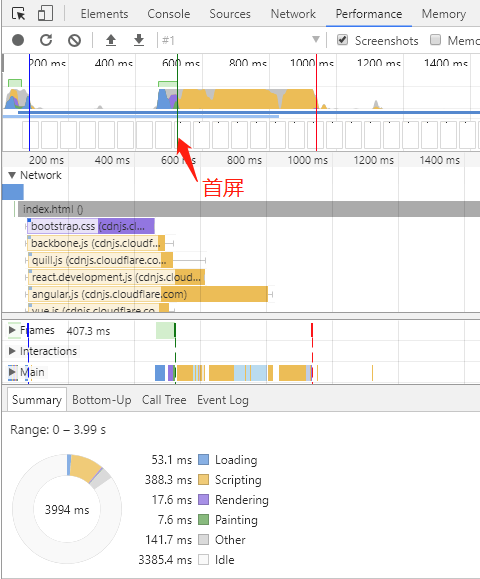
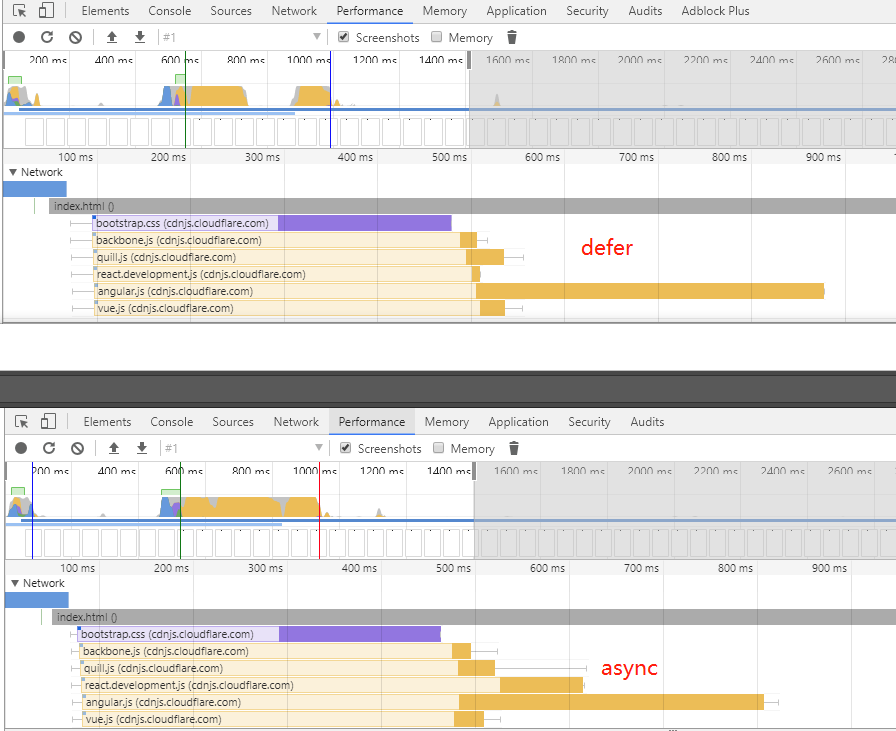
DNS 请求使用的是 UDP 协议,虽然没有 TCP 三次握手的开销,但是可能导致弱网环境下(2G,3G)数据丢失的问题。还记得之前Web 性能优化-页面重绘和回流(重排)中提到的 Google 1s 终端首屏渲染标准,假如 DNS 解析出现问题,那可能几秒甚至几十秒都首屏不了了。而且国内牛 X 的运营商的品质你也是知道的,随便劫持一下 DNS 就让你的 web 应用不见天日。
为了应对以上两个问题,HttpDNS 应运而生,原理也非常简单,将 DNS 这种容易被劫持的协议,转而使用 HTTP 协议请求 Domain 与 IP 地址之间的映射。获得正确的 IP 地址后,就不用担心 ISP 篡改数据了。
]]>
<h2>缓存梗概</h2>
<p>缓存技术几乎存在于网络技术发展的各个角落,从数据库到服务器,从服务器到网络,再从网络到客户端,缓存随处可见。跟前端有关的缓存技术主要有:DNS 缓存,HTTP 缓存,浏览器缓存,HTML5 缓存(localhost/manifest)和 service worker 中的 cache api。</p>
<h2>DNS 缓存</h2>
<p>当用户在浏览器中输入网址的地址后,浏览器要做的第一件事就是解析 DNS:</p>
<p>(1) 浏览器检查缓存中是否有域名对应的 IP,如果有就结束 DNS 解析过程。浏览器中的 DNS 缓存有时间和大小双重限制,时间一般为几分钟到几个小时不等。DNS 缓存时间过长会导致如果 IP 地址发生变化,无法解析到正确的 IP 地址;时间过短会导致浏览器重复解析域名。</p>
<p>(2) 如果浏览器缓存中没有对应的 IP 地址,浏览器会继续查找操作系统缓存中是否有域名对应的 DNS 解析结果。我们可以通过在操作系统中设置 hosts 文件来设置 IP 与域名的关系。</p>
Web 性能优化-CSS3 硬件加速(GPU 加速)https://lz5z.com/Web性能优化-CSS3硬件加速/2018-05-03T20:10:40.000Z2020-04-21T10:23:54.827ZCSS3 硬件加速简介
上一篇文章学习了重绘和回流对页面性能的影响,是从比较宏观的角度去优化 Web 性能,本篇文章从每一帧的微观角度进行分析,来学习 CSS3 硬件加速的知识。
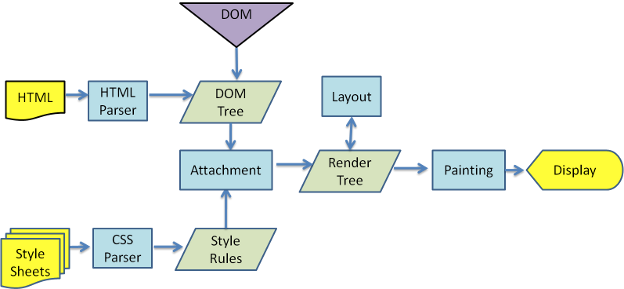
DOM Tree 和样式结构体组合后构建 render tree, render tree 类似于 DOM tree,但区别很大,render tree 能识别样式,render tree 中每个 NODE 都有自己的 style,而且 render tree 不包含隐藏的节点 (比如 display:none 的节点,还有 head 节点),因为这些节点不会用于呈现,而且不会影响呈现的节点,所以就不会包含到 render tree 中。注意 visibility:hidden 隐藏的元素还是会包含到 render tree 中的,因为 visibility:hidden 会影响布局(layout),会占有空间。根据 CSS2 的标准,render tree 中的每个节点都称为 Box (Box dimensions),理解页面元素为一个具有填充、边距、边框和位置的盒子。
// bad for (let i = 0; i < 10; i++) { el.style.left = el.offsetLeft + 5 + 'px' el.style.top = el.offsetTop + 5 + 'px' } // good let left = el.offsetLeft let top = el.offsetTop for (let i = 0; i < 10; i++) { left += 5 top += 5 } el.style.left = left + 'px' el.style.top = left + 'px'
let ul = document.getElementByTagName('ul') let man = document.createElement('li') man.innerHTML = 'man' ul.appendChild(li) let woman = document.createElement('li') woman.innerHTML = 'woman' ul.appendChild(woman)
在 IE9 之前,IE 中有一部分对象并不是原生 JavaScript 对象。例如,BOM 和 DOM 中的对象就是 C++ 实现的 COM 对象,而 COM 对象的垃圾收集机制采用的是引用计数策略。因此,即使 IE 中的 JavaScript 引擎使用标记清除策略实现,但是 JS 访问的 COM 对象依然是基于引用计数策略的。可以在 IE 中涉及到 COM 对象,就会存在循环引用的问题。
1 2 3 4
var ele = document.getElementById('some_element') var obj = newObject() obj.ele = ele ele.someObj = obj
在这个例子中一个 DOM 元素与一个原生 JS 对象之间创建了循环引用,由于 COM 的引用计数的垃圾回收策略,导致例子中的 DOM 从页面删除,也不会被垃圾回收。
《JavaScript高级程序设计》中提到了一种内存泄漏:由于 IE9 之前的版本对 JS 对象和 DOM 对象中使用的垃圾回收机制,会导致如果闭包的作用域链中保存着一个 HTML 元素,那该元素将无法销毁。
1 2 3 4 5 6
functionassignHandler () { var element = document.getElementById('someElement') element.onclick = function () { alert(element.id) } }
以上代码创建了一个作为 element 元素事件处理程序的闭包,而这个闭包则又创建了一个循环引用,匿名函数中保存了一个对 element 对象的引用,因此无法减少 element 的引用数。只要匿名函数在,element 的引用数至少是 1,因此它所占用的内存就永远无法回收。
解决办法:
1 2 3 4 5 6 7 8
functionassignHandler () { var element = document.getElementById('someElement') var id = element.id element.onclick = function () { alert(id) } element = null }
const animateDiv = document.querySelector('.animate-div') let i = 0 let inter = setInterval(() => { animateDiv.style.left = 1/3 * (++i) + '%' if (i === 300) clearInterval(inter) }, 16.7)
/** * for */ asyncfunctiona() { for (var i = 0; i < arr.length; i++) { await foo(arr[i]) } } /** * for */ asyncfunctionb() { for (let i = 0; i < arr.length; i++) { await foo(arr[i]) } } /** * for of */ asyncfunctionc() { for (let i of arr) { await foo(i) } } /** * for in */ asyncfunctiond() { for (let i in arr) { await foo(i) } } /** * while */ asyncfunctionh() { let i = 0 while (i < 5) { await foo(i++) } } /** * do while */ asyncfunctioni() { let i = 0 do { await foo(i++) } while (i < 5) }
Array.prototype.forEach = function(callback, thisArg) { var len = this.length var k = 0 while (k < len) { var kValue if (k inthis) { kValue = this[k] callback.call(thisArg, kValue, k, this) } k++ } }
for (var i = 0; i < items.length; i++) { var item = items[i].split('=') var name = decodeURIComponent(item[0]) var value = decodeURIComponent(item[1]) if (name.length) args[name] = value } return args }
functiondeepClone(o) { // if o is not an object if (!o || (typeof o) != 'object') return o let res = Array.isArray(o) ? [] : {} let keys = Object.keys(o) for (let i = 0; i< keys.length; i++) { let key = keys[i] if (typeof key === 'object') { res[key] = deepClone(o[key]) } else { res[key] = o[key] } } return res }
DDos(Distributed Denial of Service) 分布式拒绝服务。原理是利用大量的请求造成资源过载,导致服务不可用。DDoS 攻击从层次上可以分为网络层攻击和应用层攻击。
网络层 DDoS
网络层 DDoS 攻击包括 SYN Flood、ACK Flood、UDP Flood、ICMP Flood 等。
SYN Flood 攻击:主要利用 TCP 三次握手过程中存在的问题,TCP 三次握手过程是要建立连接的双方发送 SYN,SYN + ACK,ACK 数据包,攻击者构造 IP 去发送 SYN 包时,服务器返回的 SYN + ACK 就得不到应答,此时服务器会尝试重新发送,并且至少有 30s 的等待时间,导致资源和服务不可用。
import * as helpers from'helpers' import * as helpers2 from'helpers/string' import * as helpers3 from'helpers/...' import * as helpers4 from'helpers/...'
// register global utility filters. let _filters = Object.assign(helpers, helpers2, helpers3, helpers4) Object.keys(_filters).forEach(key => Vue.filter(key, _filters[key]))
于是 helper 中每个 function 都挂载在 Vue-filter 中,所以完美的避开了 tree-shaking。
// split vendor js into its own file new webpack.optimize.CommonsChunkPlugin({ name: 'vendor', minChunks(module) { // any required modules inside node_modules are extracted to vendor return ( module.resource && /\.js$/.test(module.resource) && module.resource.indexOf( path.join(__dirname, '../node_modules') ) === 0 ) } }), // extract webpack runtime and module manifest to its own file in order to // prevent vendor hash from being updated whenever app bundle is updated new webpack.optimize.CommonsChunkPlugin({ name: 'manifest', minChunks: Infinity }), // This instance extracts shared chunks from code splitted chunks and bundles them // in a separate chunk, similar to the vendor chunk // see: https://webpack.js.org/plugins/commons-chunk-plugin/#extra-async-commons-chunk new webpack.optimize.CommonsChunkPlugin({ name: 'app', async: 'vendor-async', children: true, minChunks: 3 }),
// 这里将生成的 vendor.dll.js 文件 copy 到 你需要的目录 new CopyWebpackPlugin([{ from: 'dist/vendor.dll.js', to: config.build.assetsSubDirectory, flatten: true }]), new webpack.DllReferencePlugin({ context: __dirname, manifest: require('../dist/vendor-manifest.json') }),
最后还需要在 html 中引入生成的 DLL,网上有一些教程是直接把 script 标签写入 html 中的,但是由于我们多个项目同时依赖同一份 html 模板,其中某一些项目并不需要引入 DLL,比如一些静态页面。于是使用 html-webpack-include-assets-plugin 实现按需加载。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
...pkgs.reduce((pre, current) => { let res = [new HtmlWebpackPlugin(current.plugin)] let {assets, filename} = current.plugin || {} if (pre) res = [...pre, ...res] if (assets) { return [...res, new HtmlWebpackIncludeAssetsPlugin({ files: [filename], assets: assets.map(item =>`${assetsSubDirectory}/${item}`), append: false, publicPath: assetsPublicPath })] } return res }, null),
shutdown 有如下选项: - k =>不执行任何关机操作,只发出警告信息给所有用户 - r => 重新启动计算机 - h => 关机并彻底断电 - f =>快速关机且重启动时跳过fsck - n =>快速关机不经过init程序 - c => 取消之前的定时关机 立即关机:shutdown -h now 立即重启:shutdown -r now 注意:now 不能省略
Intersection Observer API 会注册一个回调方法,每当期望被监视的元素进入或者退出另外一个元素的时候(或者浏览器的视口)该回调方法将会被执行,或者两个元素的交集部分大小发生变化的时候回调方法也会被执行。通过这种方式,网站将不需要为了监听两个元素的交集变化而在主线程里面做任何操作,并且浏览器可以帮助我们优化和管理两个元素的交集变化。
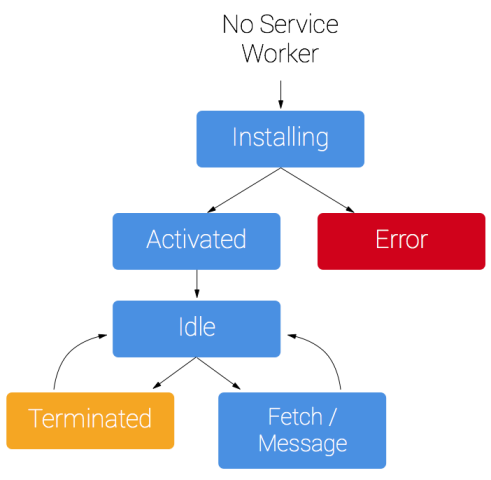
install 事件一般是被用来完成浏览器的离线缓存功能,service worker 的缓存机制是依赖 cache API 实现的。cache API 为绑定在 service worker 上的全局对象,可以用来存储网络响应发来的资源,这些资源只在站点域名内有效,并且一直存在,直到你告诉它不再存储。
缓存和返回请求
每次任何被 service worker 控制的资源被请求到时,都会触发 fetch 事件,因此我们可以利用 fetch 事件对资源响应做一些拦截操作
下面是一个使用 service worker 的 postMessage API 做的一个简单计算器,其中计算部分在 service worker 线程中完成。假如有一些比较耗时的工作,比如大量计算,或者 fetch 数据,可以将其放入 service worker 线程中,以达到提高页面响应的目的。
// 块级作用域 var name = 'Leo' if (name) { name = 'Jack'// 这里的 name 是全局变量 console.log(name) // Jack } console.log(name) // Jack // 函数作用域 var name = 'Leo' functionsayName () { var name = 'Jack' console.log(name) // Jack } console.log(name) // Leo
如果在声明一个变量的时候没有使用 var 关键字,那么变量将成为一个全局变量。
1 2 3 4
(function() { a = 'Hello World' })() alert(a) // Hello World
函数声明: function fun(arguments) {} 函数表达式: var fun = function (arguments) {}
1 2 3 4 5
add(1, 2) // 报错:Uncaught TypeError: add is not a function var add = function () { returneval(Array.prototype.join.call(arguments, '+')) } add(1, 2) // 3
函数声明会覆盖变量声明。
1 2 3 4 5
var test functiontest () { console.log('test') } console.log(typeof test) // 'function'
如果变量已经赋值,则无法别覆盖:
1 2 3 4 5
var test = 'test' functiontest () {} console.log(typeof test) // 'string' test = function () {} console.log(typeof test) // 'function'
优先级
在 JavaScript 中,一个变量以四种方式进入作用域 scope:
语言内置:所有的作用域中都有 this 和 arguments 关键字(global 没有 arguments);
var cssnext = require('cssnext'); var autoprefixer = require('autoprefixer'); var px2rem = require('postcss-px2rem'); var Ex = require('extract-text-webpack-plugin'); var webpack = require('webpack')
ERROR in ./style.css Module parse failed: D:\webpack-demo\style.css Unexpected token (1:11) You may need an appropriate loader to handle this file type. | html, body { | background-color: gray; @ ./hello.js 2:0-22
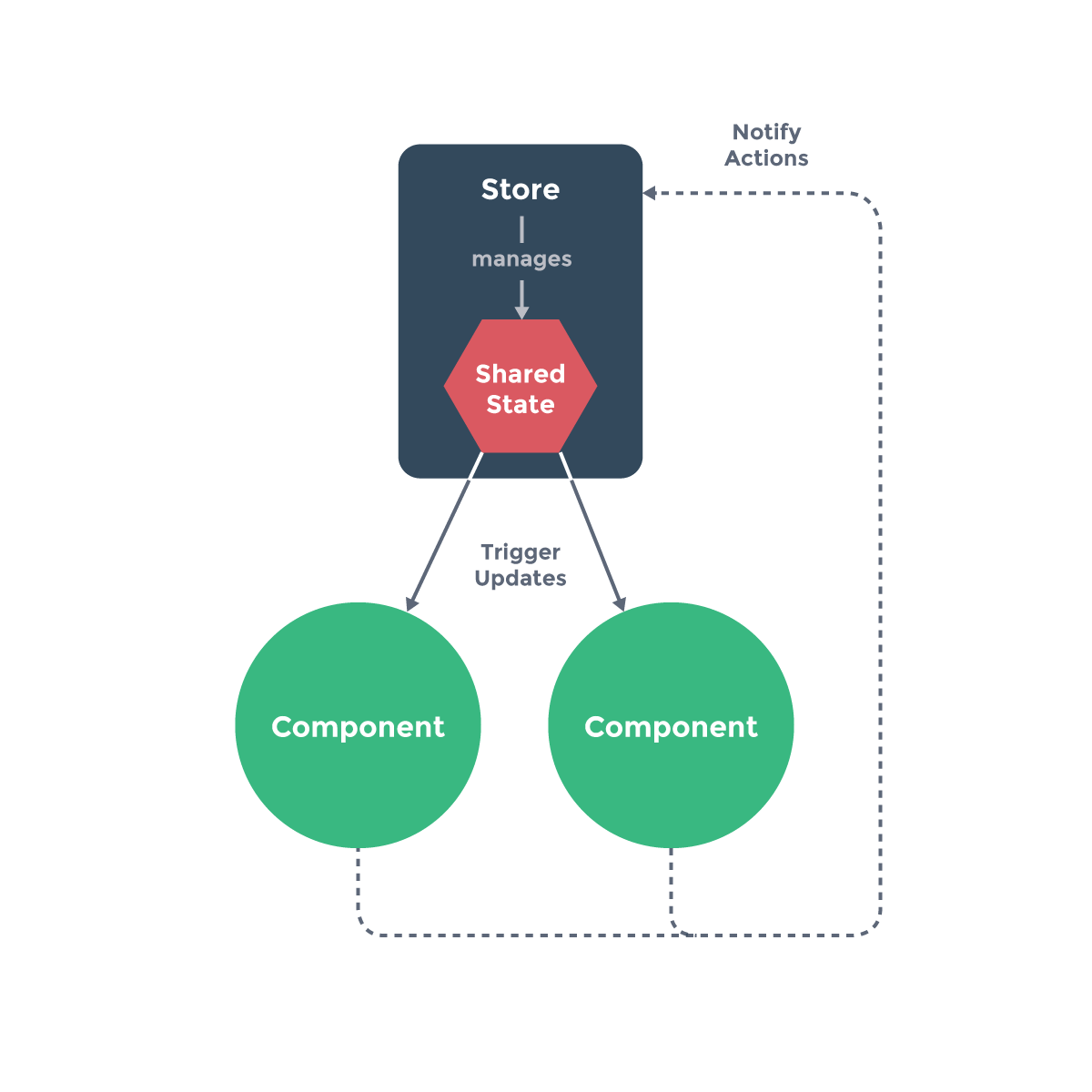
在 Vuex 中,store 是组件状态的一个容器,上面的 store 中定义了一个初始的 state 对象,和两个 mutations 函数。我们可以通过 store.state 来获取状态对象,以及通过 store.commit 方法触发状态变更。要注意的是,我们不能直接更改 store 中的状态,改变 store 中的状态的唯一途径就是显式地提交(commit) mutations。
let headers = new Headers(); headers.append('Accept', 'application/json'); let request = new Request(url, {headers: headers}); fetch(request).then(response => { console.log(response.headers); });
构建 Respondse 对象有什么用呢?通常 Response 的内容在服务端生成,但是 Fetch API 是浏览器里面的内容啊。
对了,就是为了离线应用,通过 Service Worker 浏览器能够获取请求头的内容,然后通过在浏览器中构建响应头来替换来自服务器的响应头以达到构建离线应用的目的(这方面内容以后再说)。
构建方法
1 2 3 4
let response = new Response( JSON.stringify({photos: {photo: []}}), {status: 200, headers: headers} );
steam 支持
Request 和 Response 对象中的 body 只能被读取一次,它们有一个属性叫 bodyUsed,读取一次之后设置为 true,就不能再读取了。
1 2 3 4 5 6
let res = new Response("one time use"); console.log(res.bodyUsed); //false res.text().then(v => { console.log(v); //"one time use" console.log(res.bodyUsed); // true });
Web 开发的最终目的是把数据反映到 UI 上,这时就需要对 DOM 进行操作,复杂或者频繁的 DOM 操作通常是性能瓶颈产生的原因。React 为此引入了虚拟 DOM(Virtual DOM) 的机制:开发者操作虚拟 DOM,React 在必要的时候将它们渲染到真正的 DOM 上。
Virtual DOM
基于 React 进行开发时所有的 DOM 构造都是通过虚拟 DOM 进行,每当数据变化时,React 都会重新构建整个 DOM 树,然后 React 将当前整个 DOM 树和上一次的 DOM 树进行对比,得到 DOM 结构的区别,然后仅仅将需要变化的部分更新到实际的浏览器。
同时 React 能够批处理虚拟 DOM 的刷新,在一个事件循环(Event Loop)内的两次数据变化会被合并,例如你连续的先将节点内容从 A 变成 B,然后又从 B 变成 A,React 会认为 UI 不发生任何变化。尽管每一次都需要构造完整的虚拟 DOM 树,但是因为虚拟 DOM 是内存数据,性能是极高的,而对实际 DOM 进行操作的仅仅是 Diff 部分,因而能达到提高性能的目的。
let t0 = newDate().getTime(); setInterval(()=>{ let t = newDate().getTime(), delta = t - t0; //在虚拟DOM上创建元素 let el = React.createElement("p",null,delta); //渲染到真实DOM ReactDOM.render(el,document.getElementById('root')); },16);
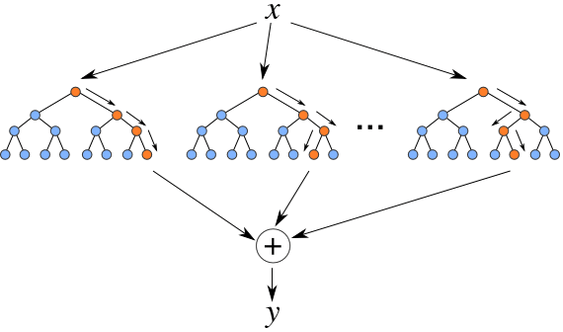
对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为 N 个,那么采样的样本也为 N 个,这选择好了的 N 个样本用来训练一个决策树,作为决策树根节点处的样本,同时使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现 over-fitting。
对于列采样,从 M 个 feature 中,选择 m 个 (m << M),即:当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这 M 个属性中选取出 m 个属性,满足条件 m << M。
DOM1 级由两个模块组成,DOM 核心(DOM Core)和 DOM HTML。其中,DOM Core 规定如何映射基于 XML 的文档结构,DOM HTML 模块则在 DOM Core 基础上加以扩展,添加了针对 HTML 的对象和方法。
DOM2 在原有的 DOM 基础上又扩充了鼠标和用户界面事件、范围、遍历(迭代 DOM 文档的方法)等细分模块,并且通过对象接口增加了对 CSS 的支持。DOM2 级引入的模块有: - DOM 视图(DOM Views):定义了追踪不同文档的视图接口。 - DOM 事件(DOM Events):定义了事件和事件处理的接口。 - DOM 样式(DOM Style):定义了基于 CSS 为元素样式的接口。 - DOM 遍历和范围(DOM Traversal and Range):定义了遍历和操作文档树的接口。
DOM3 级进一步扩展 DOM,引入了以统一方式加载和保存文档的方法——在 DOM 加载和保存(DOM Load and Save)模块中定义,新增了 DOM 验证(DOM Validation)。DOM3 级也对 DOM Core 进行了扩展,开始支持 XML 1.0 规范。
DOM0 级,DOM0 级标准本质上不存在,所谓 DOM0 只是 DOM 历史坐标中的一个参照点,具体来说,DOM0 级是指 Internet Explorer 4.0 和 Netscape Navigator 4.0 最初支持的 DHTML。
可以通过以下代码确定浏览器是否支持 DOM 模块:
1 2 3 4 5
var supportsDOM2Core = document.implementation.hasFeature('core', '2.0') var supportsDOM3Core = document.implementation.hasFeature('core', '3.0') var supportsDOM2HTML = document.implementation.hasFeature('HTML', '2.0') var supportsDOM2Views = document.implementation.hasFeature('Views', '2.0') var supportsDOM2XML = document.implementation.hasFeature('XML', '2.0')
]]>
<h2>JavaScript 与 ECMAScript 关系</h2>
<p>JavaScript = ECMAScript + DOM + BOM</p>
<p>1.ECMAScript 为 JavaScript 提供核心语言功能,是由欧洲计算机制造商协会(ECMA)39号技术委员会(TC39)制定的一种通用、跨平台、供应商中立的脚本语言和语义。ECMAScript 是一种由 ECMA 组织通过 ECMA-262 标准化的脚本程序设计语言。ECMA-262 标准没有参考 Web 浏览器,它规定了语言的语法、类型、语句、关键字、保留字、操作符、对象。</p>
<p>2.DOM (文档对象模型) 是针对 XML 但是经过扩展用于 HTML 的应用程序编程接口(API)。DOM 把 HTML 页面映射为一个多层节点结构,开发人员借助 DOM 提供的 API,可以轻松地删除,添加,替换或者修改节点。</p>
<p>3.BOM(浏览器对象模型)指的是由 Web 浏览器暴露的所有对象组成的表示模型。从根本上将 BOM 只处理浏览器窗口和框架,但是人们习惯把针对浏览器的 JavaScript 扩展也算作 BOM 的一部分,例如:浏览器弹出新窗口的功能;移动、缩放和关闭浏览器窗口的功能;navigator 对象;location 对象; screen 对象;cookies 支持;XMLHttpRequest 和 IE 的 ActiveXObject 对象。BOM 直到 HTML5 才有了规范可以遵守,在此之前每个浏览器都有自己不同的实现。</p>
Angular 双向绑定实现原理https://lz5z.com/Angular双向绑定原理/2016-12-19T21:33:09.000Z2020-04-21T10:23:54.823Z从一个 demo 讲起
用 Angular + socket.io 做了一个聊天 demo,消息通信没有问题,在 Angular 数据绑定的地方却栽了跟头:明明 model 已经发生了改变,在视图上就是看不到更新。
'use strict'; let express = require('express'); let app = express(); let http = require('http').Server(app); let io = require('socket.io')(http); let path = require('path');
最近在 ITA 写了一个聊天机器人的 Flask 服务,自己写了一些 node 单元测试脚本跑没有问题,但是测试的同学也想覆盖到所有的 case,于是就帮忙写一个 html 页面去测试,然后就遇到了下面的问题:
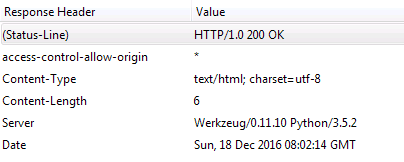
XMLHttpRequest cannot load http://localhost:8085/predict. No ‘Access-Control-Allow-Origin’ header is present on the requested resource. Origin ‘null’ is therefore not allowed access.
这个是典型的跨域问题(跨域是指:协议、域名、端口有任何一个不同,都被当做是不同的域),想想之前也了解过跨域的知识,现在借着这个机会总结一下了。关于 GET 请求的跨域,使用 JSONP 是目前最好的解决方案,各大浏览器也基本都支持 JSONP,而 jQuery,AngularJS 等前端框架也都默认添加了对 JSONP 的封装,并且这次遇到的跨域问题是 POST 请求的,于是暂时先不写关于 JSONP 的相关知识。
>>> df.head(3) A B C D 2017-01-010.1470721.2352260.1439520.831411 2017-01-020.862293-0.725103-0.1046641.265863 2017-01-030.2815110.956868-0.7411930.129071 >>> df.tail(3) A B C D 2017-01-04-0.6644750.9656531.5223921.129707 2017-01-05-1.364532-0.1678770.0784480.217550 2017-01-060.7177210.344734-0.9513640.362032
>>> df.describe() A B C D count 6.0000006.0000006.0000006.000000 mean -0.0034020.434917-0.0087380.655939 std 0.8559160.7631180.8728700.486500 min -1.364532-0.725103-0.9513640.129071 25% -0.461588-0.039724-0.5820600.253671 50% 0.2142920.650801-0.0131080.596722 75% 0.6086690.9634570.1275761.055133 max 0.8622931.2352261.5223921.265863
>>> df[0:3] A B C D 2017-01-010.1470721.2352260.1439520.831411 2017-01-020.862293-0.725103-0.1046641.265863 2017-01-030.2815110.956868-0.7411930.129071
>>> df.loc[dates[0]] A 0.147072 B 1.235226 C 0.143952 D 0.831411
多选,「A:B」 表示从 A 到 B
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
>>> df.loc[:,['A','B']] A B 2017-01-010.1470721.235226 2017-01-020.862293-0.725103 2017-01-030.2815110.956868 2017-01-04-0.6644750.965653 2017-01-05-1.364532-0.167877 2017-01-060.7177210.344734 >>> df.loc['20170102':'20170104',['A','B']] A B 2017-01-020.862293-0.725103 2017-01-030.2815110.956868 2017-01-04-0.6644750.965653 >>> df.loc['20170102',['A','B']] A 0.862293 B -0.725103 Name: 2017-01-0200:00:00, dtype: float64 >>> df.at[dates[0],'A'] 0.14707225966646126
通过下标选择
选择第四行所有元素
1 2 3 4 5
>>> df.iloc[3] A -0.664475 B 0.965653 C 1.522392 D 1.129707
选出34行,01列
1 2 3 4
>>> df.iloc[3:5,0:2] A B 2017-01-04-0.6644750.965653 2017-01-05-1.364532-0.167877
选择单个元素
1 2
>>> df.iloc[1,1] >>> df.iat[1,1]
比较运算
1 2 3 4 5 6
>>> df[df.A > 0] A B C D 2017-01-010.1470721.2352260.1439520.831411 2017-01-020.862293-0.725103-0.1046641.265863 2017-01-030.2815110.956868-0.7411930.129071 2017-01-060.7177210.344734-0.9513640.362032
选出大于0 的全部元素,没有填充的值等于 NaN
1 2 3 4 5 6 7 8
>>> df[df > 0] A B C D 2017-01-010.1470721.2352260.1439520.831411 2017-01-020.862293 NaN NaN 1.265863 2017-01-030.2815110.956868 NaN 0.129071 2017-01-04 NaN 0.9656531.5223921.129707 2017-01-05 NaN NaN 0.0784480.217550 2017-01-060.7177210.344734 NaN 0.362032
isin() 函数:是否在集合中
1 2 3 4 5 6 7 8 9 10 11 12 13 14
>>> df2 = df.copy() >>> df2['E'] = ['one', 'one','two','three','four','three'] >>> df2 A B C D E 2017-01-010.1470721.2352260.1439520.831411 one 2017-01-020.862293-0.725103-0.1046641.265863 one 2017-01-030.2815110.956868-0.7411930.129071 two 2017-01-04-0.6644750.9656531.5223921.129707 three 2017-01-05-1.364532-0.1678770.0784480.217550 four 2017-01-060.7177210.344734-0.9513640.362032 three >>> df2[df2['E'].isin(['two','four'])] A B C D E 2017-01-030.2815110.956868-0.7411930.129071 two 2017-01-05-1.364532-0.1678770.0784480.217550 four
设置
按照 index 给 DataFrame 添加新的列:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
>>> s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20170102', periods=6)) >>> s1 2017-01-021 2017-01-032 2017-01-043 2017-01-054 2017-01-065 2017-01-076 Freq: D, dtype: int64 >>> df['F'] = s1 >>> df A B C D F 2017-01-010.1470721.2352260.1439520.831411 NaN 2017-01-020.862293-0.725103-0.1046641.2658631.0 2017-01-030.2815110.956868-0.7411930.1290712.0 2017-01-04-0.6644750.9656531.5223921.1297073.0 2017-01-05-1.364532-0.1678770.0784480.2175504.0 2017-01-060.7177210.344734-0.9513640.3620325.0
>>> df2 = df.copy() >>> df2[df2 > 0] = -df2 >>> df2 A B C D F 2017-01-010.000000-1.000000-0.143952-5 NaN 2017-01-02-0.862293-0.725103-0.104664-5-1.0 2017-01-03-0.281511-0.956868-0.741193-5-2.0 2017-01-04-0.664475-0.965653-1.522392-5-3.0 2017-01-05-1.364532-0.167877-0.078448-5-4.0 2017-01-06-0.717721-0.344734-0.951364-5-5.0
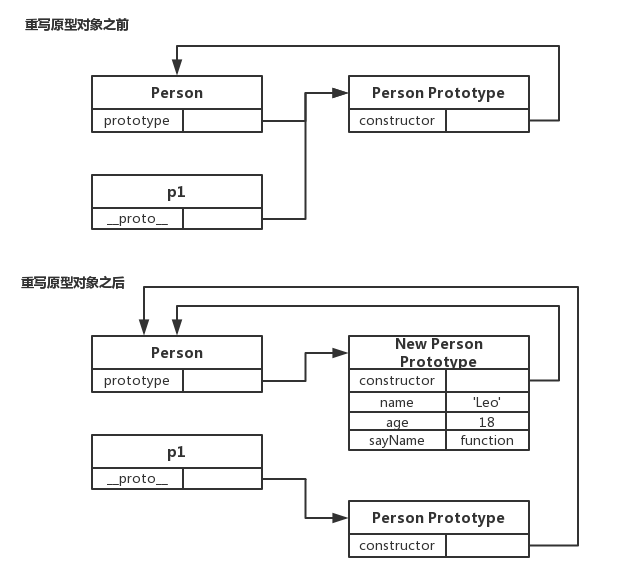
functionPerson () {} let p1 = new Person() Person.prototype = { constructor: Person, name: 'JavaScript', age: 18, sayName: function () { console.log(this.name) } } p1.sayName() // p1.sayName is not a function
functioncreatePerson(name, age, job) { let o = newObject() o.name = name o.age = age o.job = job o.sayName = function () { console.log(this.name) } return o } let leo = createPerson('Leo', 18, "Engineer")
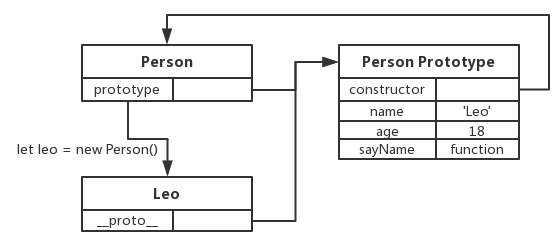
functionPerson(name, age, job) { this.name = name this.age = age this.job = job this.sayName = function() { console.log(this.name) } } let leo = new Person('Leo', 18, "Engineer") let jack = new Person('Jack', 18, "Engineer")
构造函数模式与工厂模式有以下不同:
没有显式的创建对象;
直接将属性和方法赋给了this对象;
没有return语句;
构造函数应该以大写字母开头,使用 new 操作符。new 操作符创建对象经历以下 4 个步骤:
创建新的对象;
将构造函数的作用域赋给新对象(因此 this 就指向了这个新对象);
执行构造函数中的代码(为这个新对象添加属性);
返回新对象;
生成的对象 leo 中有一个 constructor 属性,该属性指向 Person,并且可以用 instanceof 做类型检测。
1 2 3
leo.constructor === Person // true leo instanceofObject// true leo instanceof Person // true
构造函数的缺点在于每个方法都要在每个实例上重新创建一遍。在前面例子中,leo 和 jack 都有一个名为 sayName 的方法,但是这两个方法不属于同一个对象。
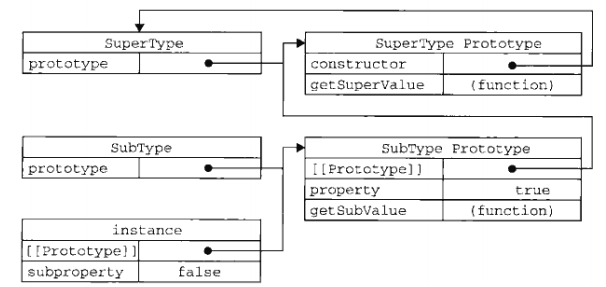
functionPerson() {} Person.prototype.name = 'Leo' Person.prototype.age = 18 Person.prototype.sayName = function() { console.log(this.name) } let leo1 = new Person let leo2 = new Person leo1.sayName() leo2.sayName()
在此,我们将 sayName() 方法和所有的属性直接添加到了 Person 的 prototype 属性中,构造函数变成了空函数,而通过 new 创建出来的对象具有相同的属性和方法。但是与构造函数模式不同对的是,新对象的这些属性和方法是由所有的实例共享的,也就是说
functionPerson(name, age) { this.name = name this.age = age if (typeofthis.sayName != 'function') { Person.prototype.sayName = function() { console.log(this.name) } } } let leo = new Person('Leo', 18) leo.sayName()
Person 是一个构造函数,通过 new Person() 来生成实例对象。每当一个 Person 的对象生成时,Person 内部的代码都会被调用一次。
如果去掉 if 的话,你每 new 一次(即每当一个实例对象生产时),都会重新定义一个新的函数,然后挂到 Person.prototype.sayName 属性上。而实际上,你只需要定义一次就够了,因为所有实例都会共享此属性的。而加上 if 后,只在 new 第一个实例时才会定义 sayName 方法,之后就不会了。
假设除了sayName 方法外,你还定义了很多其他方法,比如 sayBye、cry、smile 等等。此时你只需要把它们都放到对 sayName 判断的 if 块里面就可以了。
functionPerson(name, age) { let o = newObject() o.name = name o.age = age o.sayName = function() { console.log(this.name) } return o } let leo = new Person('Leo', 18) leo.sayName()
在这个例子中,Person 函数创建了一个新对象,并以相应的属性和方法初始化该对象,然后返回这个对象。除了使用 new 操作符并把使用的包装函数叫做构造函数外,这个模式跟工厂模式一模一样。构造函数在不返回值的情况下,默认会返回新的对象实例。
let obj = {}; obj.2 = 2; //Uncaught SyntaxError: Unexpected number obj.12s = '12s'; //Uncaught SyntaxError: Invalid or unexpected token
而使用字面量的形式创建对象,或者用 对象[属性名] 的方法,却没有这样的限制:
1 2 3 4 5 6 7 8 9
let o = {}; let obj = { x: 1, 2: 2, o: 'object', {name: 'Leo'}: 'object' }; obj['12s'] = '12s'; obj[{name: 'Leo'}] = 'object'; //使用 对象[属性名] 的方式甚至可以把对象当做属性名传入
此时 obj 里面的属性 2 是一个整数吗?
1 2 3 4 5 6 7 8
for (let i in obj) { console.log(typeof i, i, obj[i]); } // string 2 2 // string x 1 // string o object // string 12s 12s // string [object Object] object
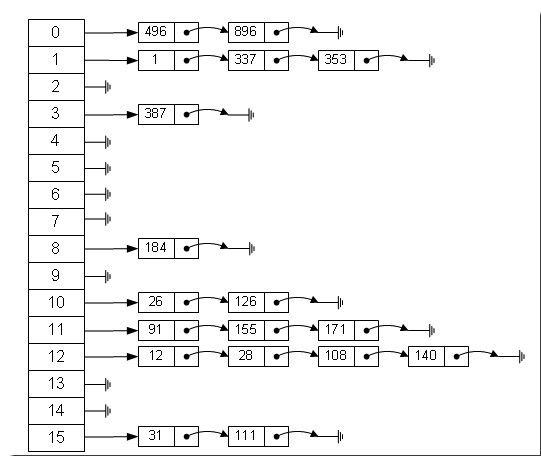
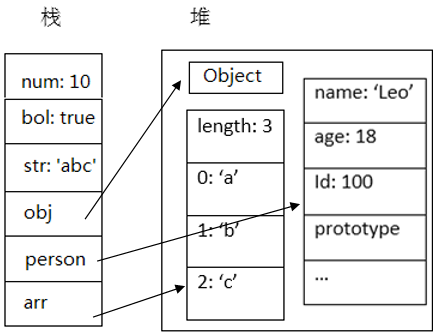
functionPerson(id, name, age) { this.id = id; this.name = name; this.age = age; } let num = 10; let bol = true; let obj = newObject; let arr = ['a', 'b', 'c']; let person = new Person(100, 'Leo', 18);
scala> val lines = sc.textFile("test.txt") scala> val lineLengths = lines.map(s => s.length) scala> val totalLength = lineLengths.reduce((a, b) => a + b)) totalLength: Int = 30
let o = newObject; // 或者 o = {} o.constructor === Object; // true let a = newArray// 或者 a = [] a.constructor === Array; // true let n = newNumber(3); // 或者 n = 3 n.constructor === Number; // true
let name = 'Leo'; let Leo = Object.defineProperty({}, 'name', { value: name, // A property cannot both have accessors and be writable or have a value get: function() { return name; } });
cwd [String] Current working directory of the child process
env [Object] Environment key-value pairs
argv0 [String] Explicitly set the value of argv[0] sent to the child process. This will be set to command if not specified.
stdio [Array] | [String] Child’s stdio configuration. (See options.stdio)
detached [Boolean] Prepare child to run independently of its parent process. Specific behavior depends on the platform, see options.detached)
uid [Number] Sets the user identity of the process. (See setuid(2).)
gid [Number] Sets the group identity of the process. (See setgid(2).)
shell [Boolean] | [String] If true, runs command inside of a shell. Uses ‘/bin/sh’ on UNIX, and ‘cmd.exe’ on Windows. A different shell can be specified as a string. The shell should understand the -c switch on UNIX, or /d /s /c on Windows. Defaults to false (no shell).
"use strict"; var f = function() { returnarguments.callee; }; f(); // TypeError: 'caller', 'callee', and 'arguments' properties may not be accessed on strict mode functions or the arguments objects for calls to them
简单明了,expand 第一个参数 deep 是一个 Boolean 型参数,如果为true的话,就展开当前结点以及子结点的所有子结点。
于是没有多加思考就用了。在开发测试环节一直没有出现什么问题,可是到了 Production 测试,帮忙测试的同学发现: 在操作树的时候,有时候浏览器会崩溃。刚开始以为是特殊情况,浏览器问题之类的,没有在意。可是不断地测试发现浏览器崩溃的情况是可复现的,就是在某几个固定的树展开的时候会出现这个问题。可见这不是浏览器的问题,是我代码的问题。
/** * Expand this node. * @param {Boolean}deep (optional) True to expand all children as well * @param {Boolean}anim (optional) false to cancel the default animation * @param {Function}callback (optional) A callback to be called when * expanding this node completes (does not wait for deep expand to complete). * Called with 1 parameter, this node. * @param {Object}scope (optional) The scope (this reference) in which the callback is executed. Defaults to this TreeNode. */ expand : function(deep, anim, callback, scope){ if(!this.expanded){ if(this.fireEvent('beforeexpand', this, deep, anim) === false){ return; } if(!this.childrenRendered){ this.renderChildren(); } this.expanded = true; if(!this.isHiddenRoot() && (this.getOwnerTree().animate && anim !== false) || anim){ this.ui.animExpand(function(){ this.fireEvent('expand', this); this.runCallback(callback, scope || this, [this]); if(deep === true){ this.expandChildNodes(true, true); } }.createDelegate(this)); return; }else{ this.ui.expand(); this.fireEvent('expand', this); this.runCallback(callback, scope || this, [this]); } }else{ this.runCallback(callback, scope || this, [this]); } if(deep === true){ this.expandChildNodes(true); } }
expandChildNodes 的源码如下
1 2 3 4 5 6 7 8 9 10 11 12
/** * Expand all child nodes * @param {Boolean}deep (optional) true if the child nodes should also expand their child nodes */ expandChildNodes : function(deep, anim) { var cs = this.childNodes, i, len = cs.length; for (i = 0; i < len; i++) { cs[i].expand(deep, anim); } }




 的工作模式,主要是把项目的代码结构给几位同事讲一下,还有一些比较容易让人困惑的点,才发现我对项目是如此熟悉,大部分代码如数家珍。
的工作模式,主要是把项目的代码结构给几位同事讲一下,还有一些比较容易让人困惑的点,才发现我对项目是如此熟悉,大部分代码如数家珍。 。当然跳槽也是有成本的,现在已经快要九月份了,跳槽相当于亏了几个月的年终奖,而且去深圳还要租房,每周往返深圳珠海还要不菲的路费,这些都是代价。粗略一算,可能未来几个月会过得更穷。再加上今年投资亏了一些,P2P 暴雷亏了一些,内推奖金没拿到,我感觉今年我就是跟钱过不去 😢。
。当然跳槽也是有成本的,现在已经快要九月份了,跳槽相当于亏了几个月的年终奖,而且去深圳还要租房,每周往返深圳珠海还要不菲的路费,这些都是代价。粗略一算,可能未来几个月会过得更穷。再加上今年投资亏了一些,P2P 暴雷亏了一些,内推奖金没拿到,我感觉今年我就是跟钱过不去 😢。
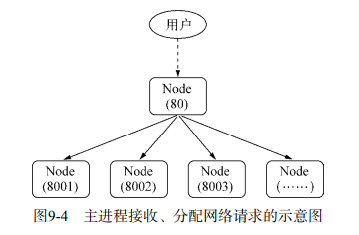
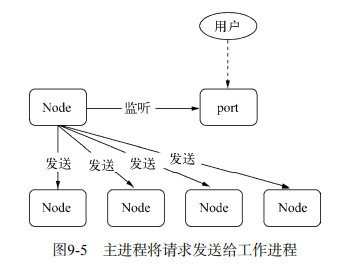
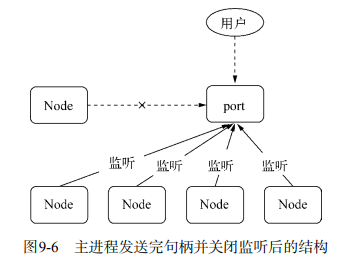
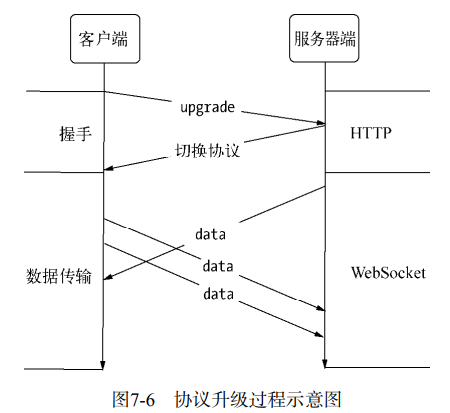
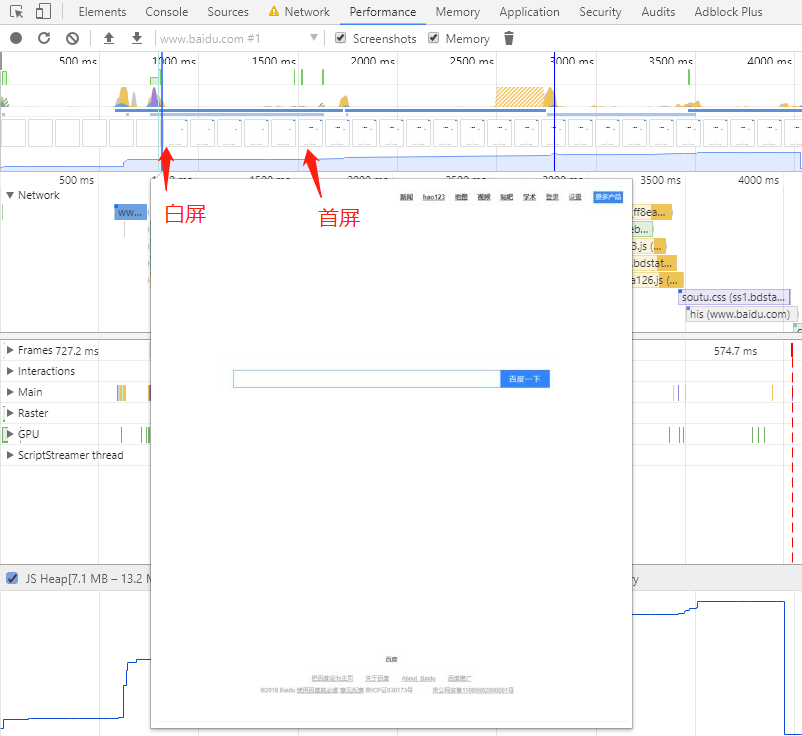
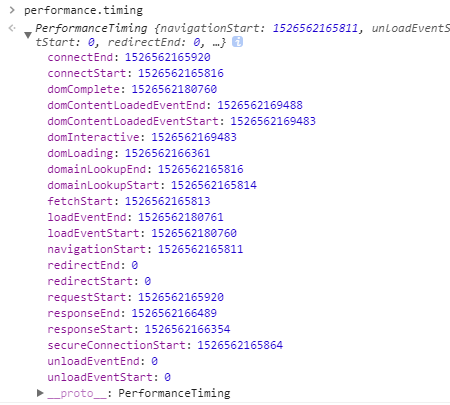
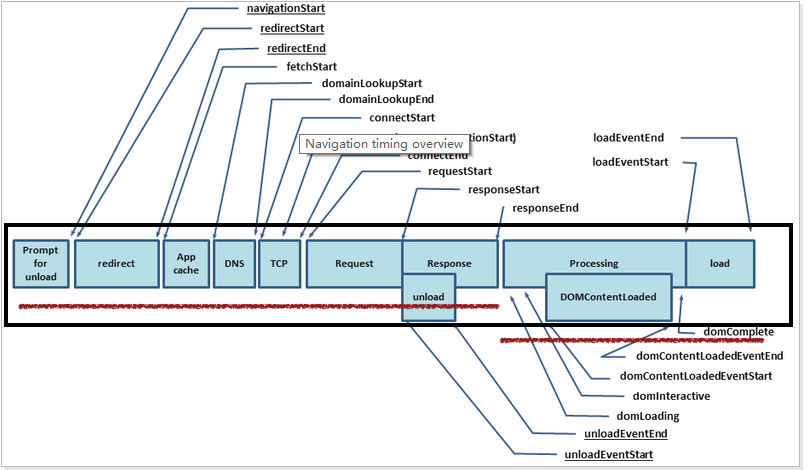

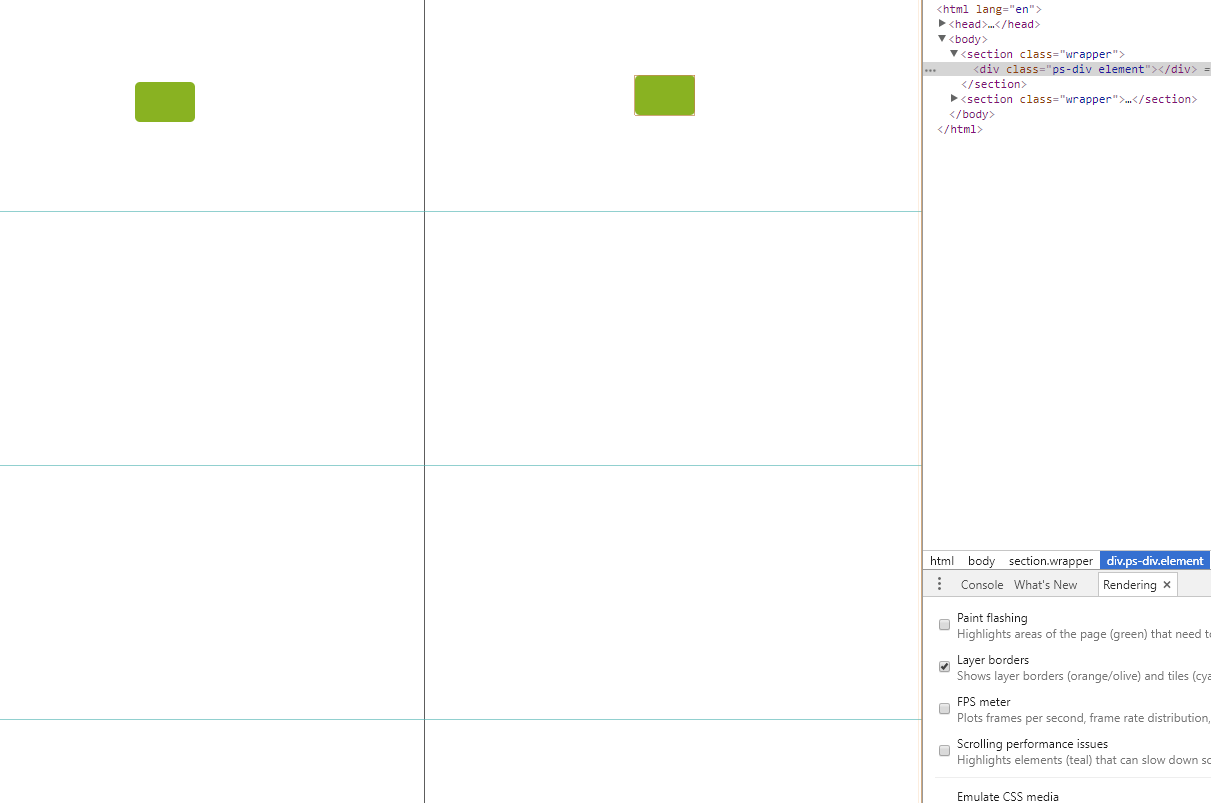
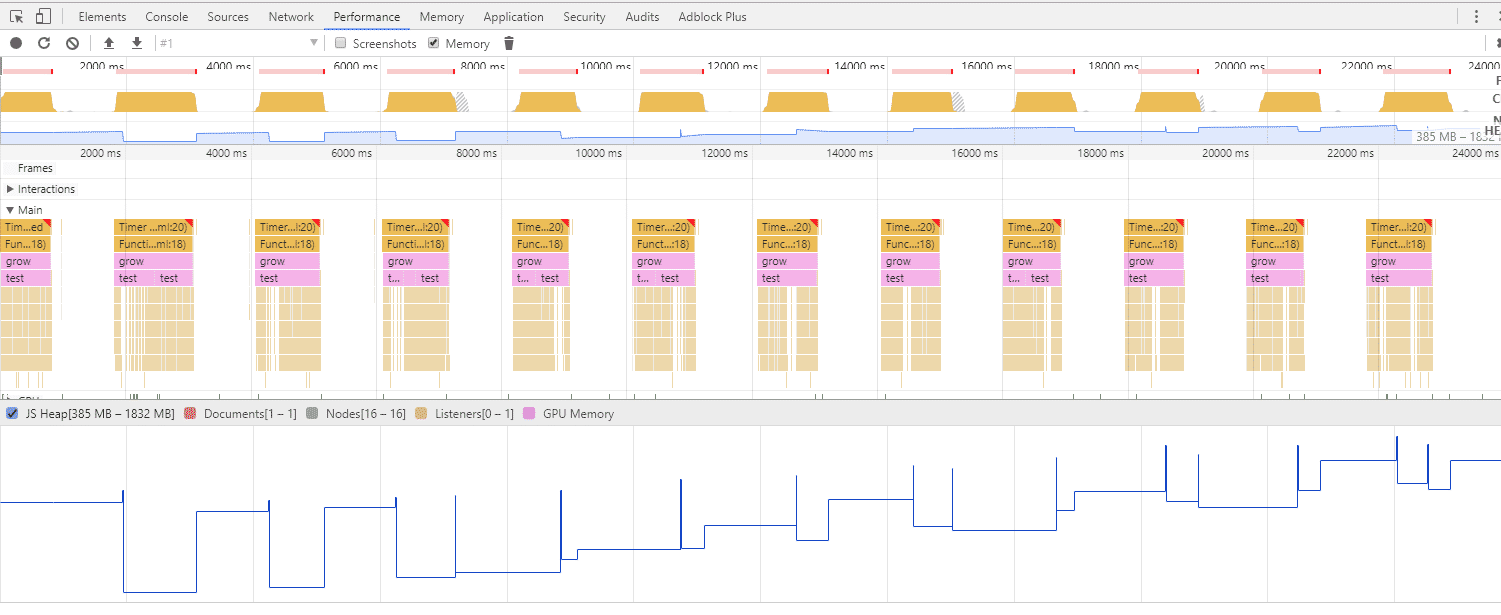
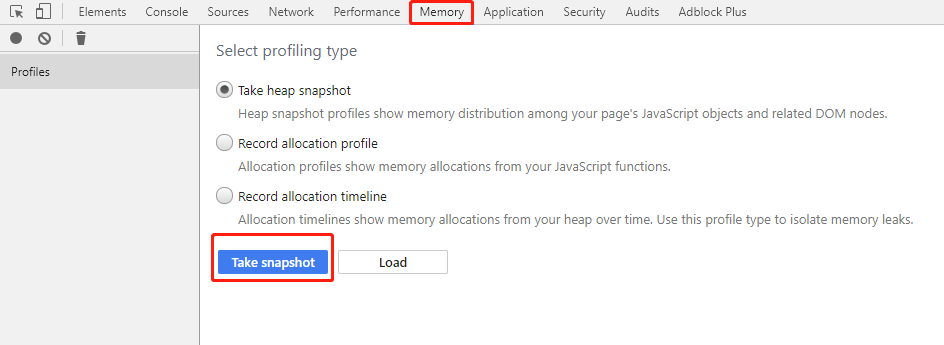
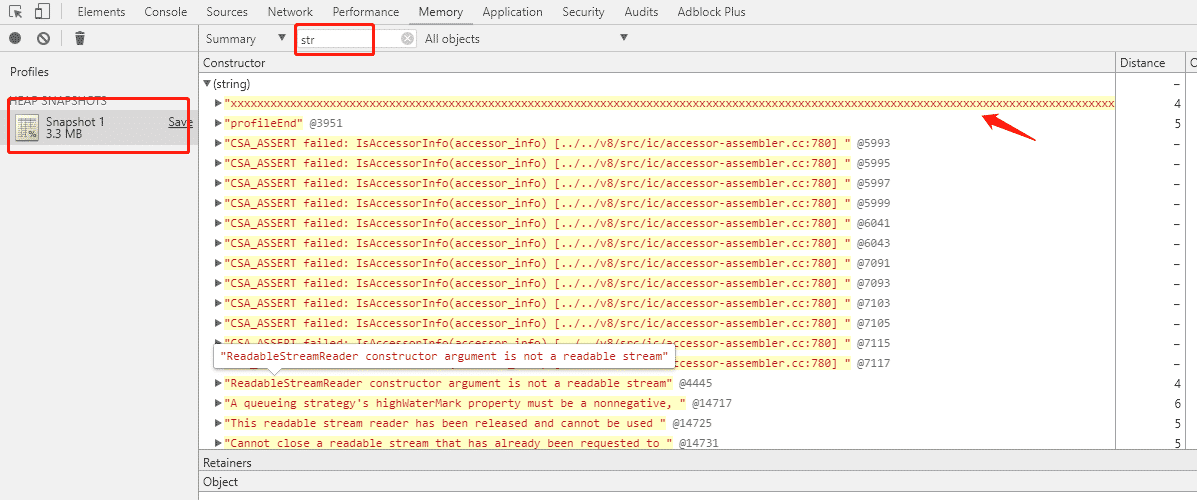
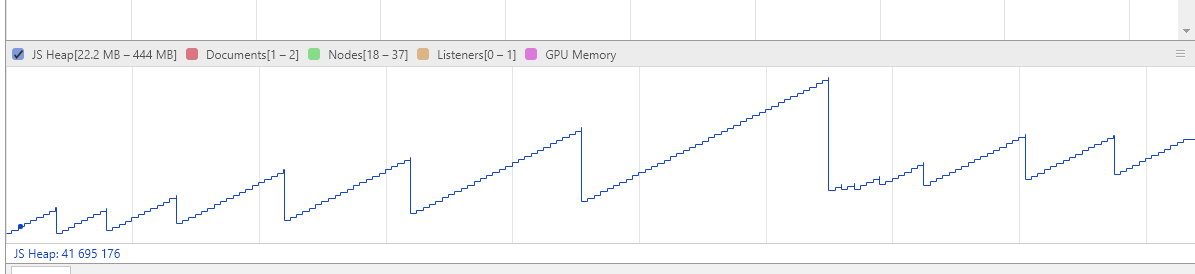




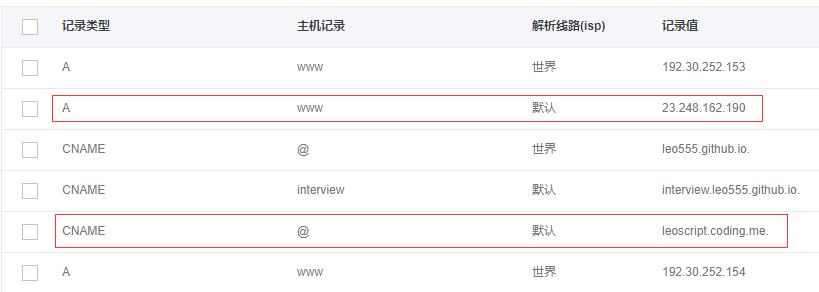
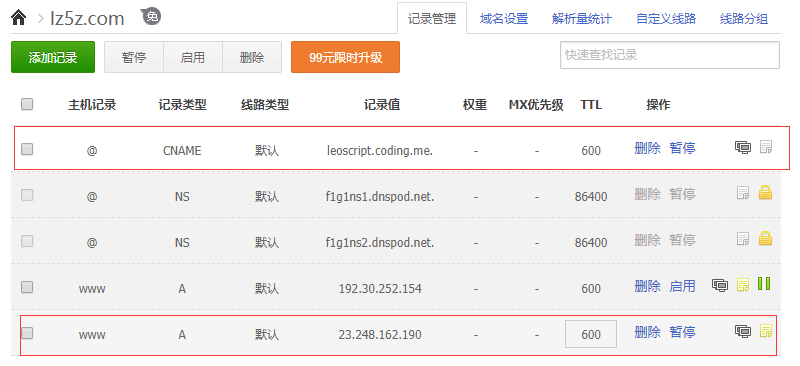


























 。还有一个要吐槽金山的是,新到职,没有新电脑用,为什么大家都有 mac 用,我只能用 win?
。还有一个要吐槽金山的是,新到职,没有新电脑用,为什么大家都有 mac 用,我只能用 win?

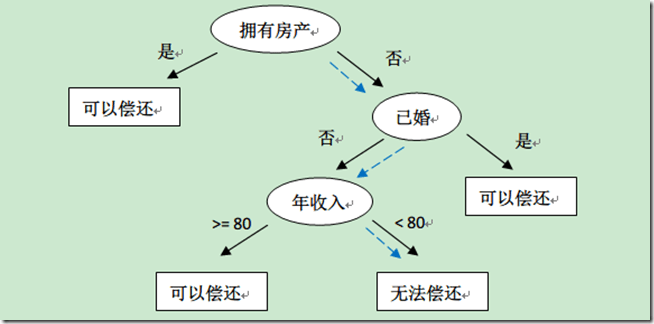
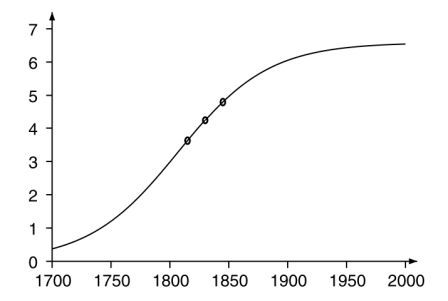 [比利时的人口增长数量图]
[比利时的人口增长数量图]
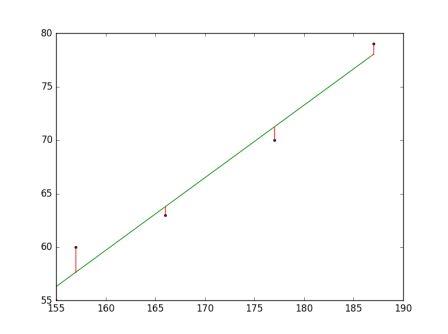
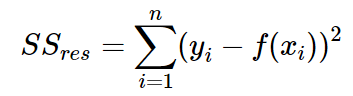
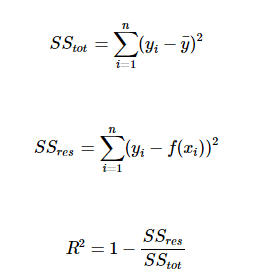
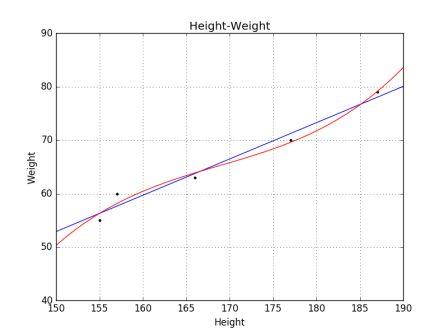

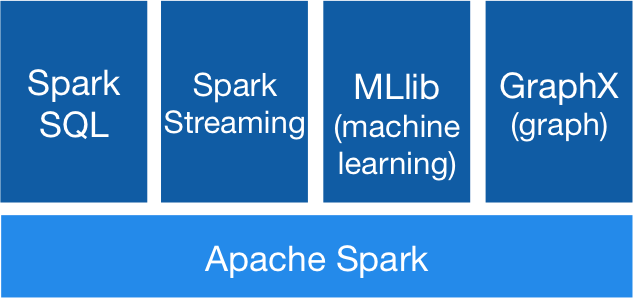 [图片摘自[Spark 官网](http://spark.apache.org/)]
[图片摘自[Spark 官网](http://spark.apache.org/)]
 。Vue使用的是 ES5 提供的 Object.defineProperty() 结合发布者-订阅者模式,通过Object.defineProperty() 来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
。Vue使用的是 ES5 提供的 Object.defineProperty() 结合发布者-订阅者模式,通过Object.defineProperty() 来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。