简介
本项目ITA的一个大数据学习的项目,以下是我的大体思路。
- 使用node.js爬虫每天从「新浪微博」上爬取一定数量的微博。主要实现登录,抓取发布微博,抓取关注人和粉丝的功能,暂时把数据存放在MongoDB中。
- 对微博进行分词,分词是非常复杂的功能,需要机器学习训练模型,因此采用哈工大开源项目「LTP-Cloud」直接调用现成API。感谢哈工大社会计算与信息检索研究中心 (HIT-SCIR)。
- 然后对分词后的词语进行情绪分析,这里使用大连理工大学林鸿飞教授带领全体教研室成员整理而成的「情感词汇本体库」。
- 最后使用spark将情绪分析结果进行数据整合。
weibo_crawler
第一部分是准备数据,随机爬取50w左右的微博用户,然后每天爬取他们前一天发布的微博作为本项目的数据源。
爬取用户信息采用递归的方式,随机以某个用户为起点,然后爬取该用户的关注和粉丝,然后递归地爬取关注和粉丝的信息。只需要得到用户名、用户ID即可。
由于新浪微博对爬虫有限制,因此爬取用户微博的时候采用定时器的方式。
由于只有登录了才能获取某个用户的个人信息和关注粉丝信息,而微博爬虫的难点就在于用户登录。
使用HttpFox抓取登录时候的http请求,发现微博登录分为两部分,第一部分是预登陆,第二部分是登录,需要传递用户名、密码等信息。使用 request 模拟这个登录过程。
抓取一定的用户后,每天定时爬取这些用户前一天发布的微博。使用cheerio 对返回的页面信息进行解析。
解析页面是一个难度不大,但是非常繁琐的过程,因为微博页面中有很多「无用」的Dom元素,比如广告啊,热门话题啊,还有好友动态之类的跟本项目完全无关。于是使用正则表达式先把关键信息提取,再使用cheerio解析,速度可以接受。
中途遇到一个问题,就是有时候拿不到数据,分析原因可能有三种:
1. 网络原因
2. 可能是新浪限制
3. 关注和粉丝不一定是“人”
采用的解决方案:
1. 对抓取微博失败的,Retry 5次
2. 放弃非人类
什么是非人类呢?我在抓取一个人的关注列表的时候发现
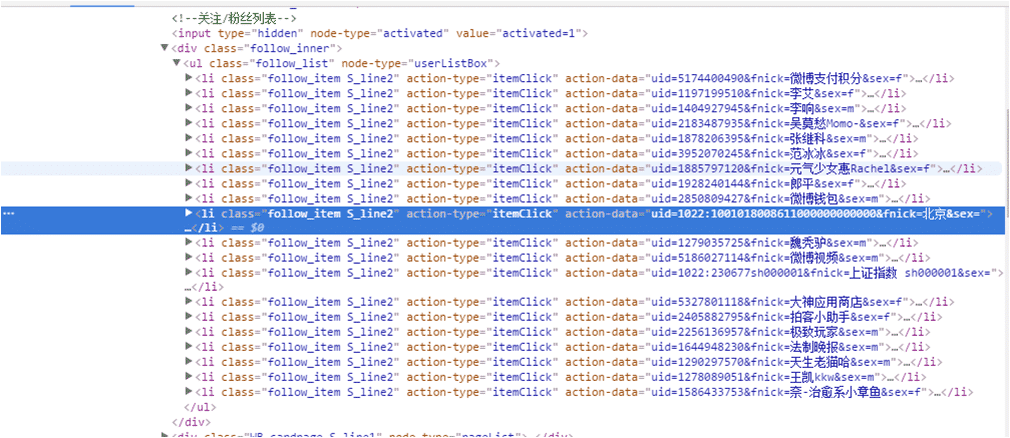
原来「北京」并不是一个用户,而是一个话题,打开「北京」页面发现它的Dom结构与普通用户的Dom结构并不相同,于是果断放弃非人类。
微博分词 Big Bang
分词就是把一句话变成一个一个单词的过程。举个栗子吧:
我是中国人。
我 - 是 - 中国 - 人
前几天锤子M1/M1L发布会上最大的亮点就是这个Big Bang功能,让手机端对文字地操作更进一步。
分词难在哪里
国务院总理李克强调研上海外高桥时提出,支持上海积极探索新机制。
- 正确的分词结果:
国务院/ 总理/ 李克强/ 调研/ 上海/ 外高桥/ 时/ 提出/ ,/ 支持/ 上海/ 积极/ 探索/ 新/ 机制/ 。 - 错误的分词结果
国务院/ 总理/ 李克/ 强调/ 研/ 上海 …
解决方案
本项目采用语言技术平台(Language Technology Platform,LTP)
语言技术平台是哈工大社会计算与信息检索研究中心历时十年研制的一整套开放中文自然语言处理系统。
使用方式有两种,Get和Post。本项目采用Post的方式:
1 | var url = 'http://api.ltp-cloud.com/analysis/'; |
callback 里面会传回来分词后的结果。
情绪分析
情绪分析是将一个词语分出词性种类、情感类别、情感强度及极性,国外比较有影响的Ekman的6大类情感分类。
比如:

中文情感词汇本体
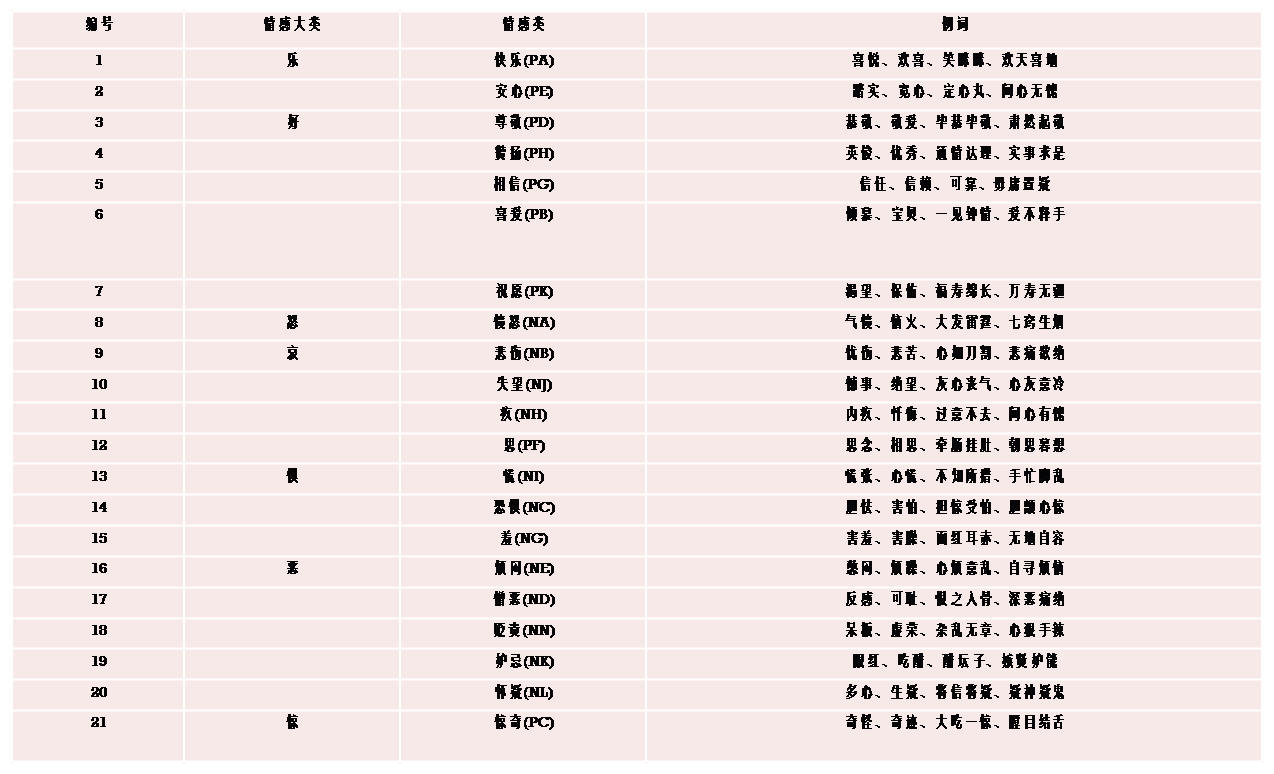
大连理工大学林鸿飞教授带领全体教研室成员整理而成的「情感词汇本体库」,是目前最权威的中文情绪词典,共含有情感词共计27466个。
情感分类
- 情感分为7大类(乐,好,怒,哀,惧,恶,惊)21小类。
- 情感强度分为1,3,5,7,9五档,9表示强度最大,1为强度最小。
- 词性种类一共分为7类,分别是名词(noun),动词(verb),形容词(adj),副词(adv),网络词语(nw),成语(idiom),介词短语(prep)。
- 极性标注,0代表中性,1代表褒义,2代表贬义,3代表兼有褒贬两性。
下图是一些示例:
情绪分析存在的问题
-
只能分析词汇,不能分析语法结构
快乐都是别人的,高兴一天天离我而去
分析结果: PA5+PA5 -
自定义情绪算法并不能很好的反应情绪值
词性: 褒义1; 贬义-1; 中性和两性0;
算法 : ∑ (词性*强度) -
Cost比较大
140字的微博分词后如果有80个词,需要比较80次。如果一次分析200条微博,需要比较200*80=16000次
解决方案
真正想要解决情绪分析还是要靠机器学习和人工智能。
Google于2016年5月13号开源自然语言理解技术SyntaxNet,并且支持中文。
准备学习之。