背景
上次的 ITA 项目开始接触机器学习相关的知识,从本文开始,我将学习并介绍机器学习最常用的几种算法,并使用 scikit-learn 相关模型完成相关算法的 demo。
线性回归
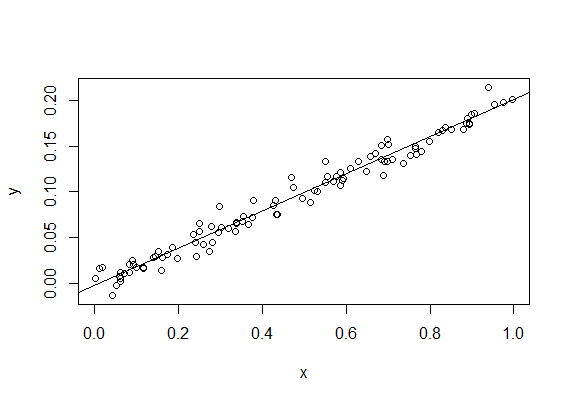
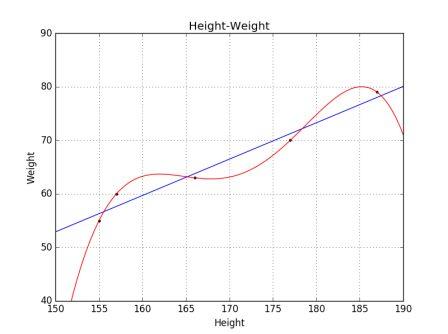
线性回归,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。我们通过拟合最佳直线来建立自变量和因变量的关系,这条最佳直线叫做回归线,并且用 Y= a*x + b这条线性等式来表示。
理解线性回归可以想象一下一般人身高与体重之间的关系,在不能准确测试体重的情况下,按照身高进行排序,也能大体得出体重的大小。这是现实生活中使用线性回归的例子。
在这个例子中,Y 是体重(因变量),x 是身高(自变量),a 和 b 分别为斜率和截距,可以通过最小二乘法获得。
身高体重
准备数据
自己伪造了一些数据
1 | import matplotlib.pyplot as plt |
创建并拟合模型
1 | from sklearn.linear_model import LinearRegression |
上述代码中 sklearn.linear_model.LinearRegression 类是一个估计器(estimator)。估计器依据观测值来预测结果。在 scikit-learn 里面,所有的估计器都带有:
- fit()
- predict()
fit() 用来分析模型参数,predict() 是通过 fit()算出的模型参数构成的模型,对解释变量进行预测获得的值。
因为所有的估计器都有这两种方法,所有 scikit-learn 很容易实现不同的模型。
线性回归分类
线性回归的两种主要类型是一元线性回归和多元线性回归。一元线性回归的特点是只有一个自变量。多元线性回归则存在多个自变量。找最佳拟合直线的时候,你可以拟合到多项或者曲线回归。这些就被叫做多项或曲线回归。
一元线性回归
一元线性回归模型是 Y= a*x + b,求解一元线性回归模型的本质就是求解参数 a 和 b 的过程,最常用的方法为最小二乘法。
残差预测值
模型的残差是训练样本点与线性回归模型的纵向距离
1 | # 残差预测值 |
如图所示:
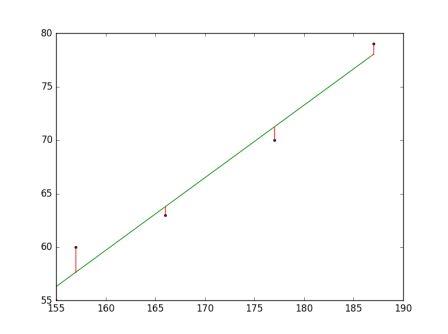
我们可以通过残差之和最小化实现最佳拟合,也就是说模型预测的值与训练集的数据最接近就是最佳拟合。对模型的拟合度进行评估的函数称为残差平方和(residual sum of squares)成本函数。就是让所有训练数据与模型的残差的平方之和最小化,如下所示:
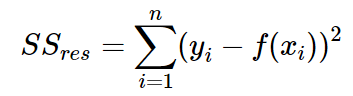
其中, yi 是观测值, f(xi)f(xi) 是预测值。
1 | import numpy as np |
残差平方和: 2.05
模型评估
使用线性回归得出模型后,我们可以用 R 方(r-squared)评估模型的效果。R方也叫确定系数(coefficient of determination),表示模型对现实数据拟合的程度。
一元线性回归中R方等于皮尔逊积矩相关系数(Pearson product moment correlation coefficient或Pearson’s r)的平方。这种方法计算的R方一定介于0~1之间的正数。其他计算方法,包括scikit-learn中的方法,不是用皮尔逊积矩相关系数的平方计算的,因此当模型拟合效果很差的时候R方会是负值。
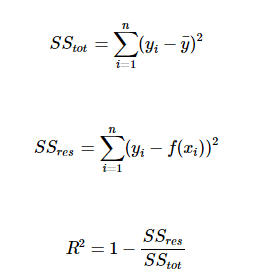
LinearRegression的score方法可以计算R方
1 | ## 测试集 |
R 方: 0.898422638707
R 方是 0.898 说明测试集里面大多数的数据都可以通过模型解释
多元回归
多元回归即存在多个自变量,比如影响体重的因素不仅仅有身高,还有胸围,假设 x 中的第一个参数为身高,第二个参数为胸围。
1 | from sklearn.linear_model import LinearRegression |
Predicted: 56.05, Target: [56]
Predicted: 60.03, Target: [63]
Predicted: 61.30, Target: [63]
Predicted: 65.56, Target: [72]
Predicted: 82.42, Target: [80]
R-squared: 0.83
多项式回归
上面两个例中,都假设自变量和响应变量的关系是线性的。真实情况未必如此,现实世界中的曲线关系都是通过增加多项式实现的,其实现方式和多元线性回归类似。在 scikit-learn 中,我们使用 PolynomialFeatures 构建多项式回归模型。下面比较多项式回归和线性回归的区别。
1 | from sklearn.preprocessing import PolynomialFeatures |
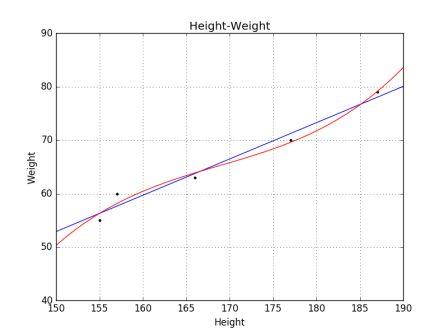
拟合过度
我们不断改变 polynomial_featurizer = PolynomialFeatures(degree=3) 中 degree 的参数,当 degree = 5 的时候曲线经过所有的点,这种情况就成为拟合过度(over-fitting)。当模型出现拟合过度的时候,并没有从输入和输出中推导出一般的规律,而是记忆训练集的结果,这样在测试集的测试效果就不好了。